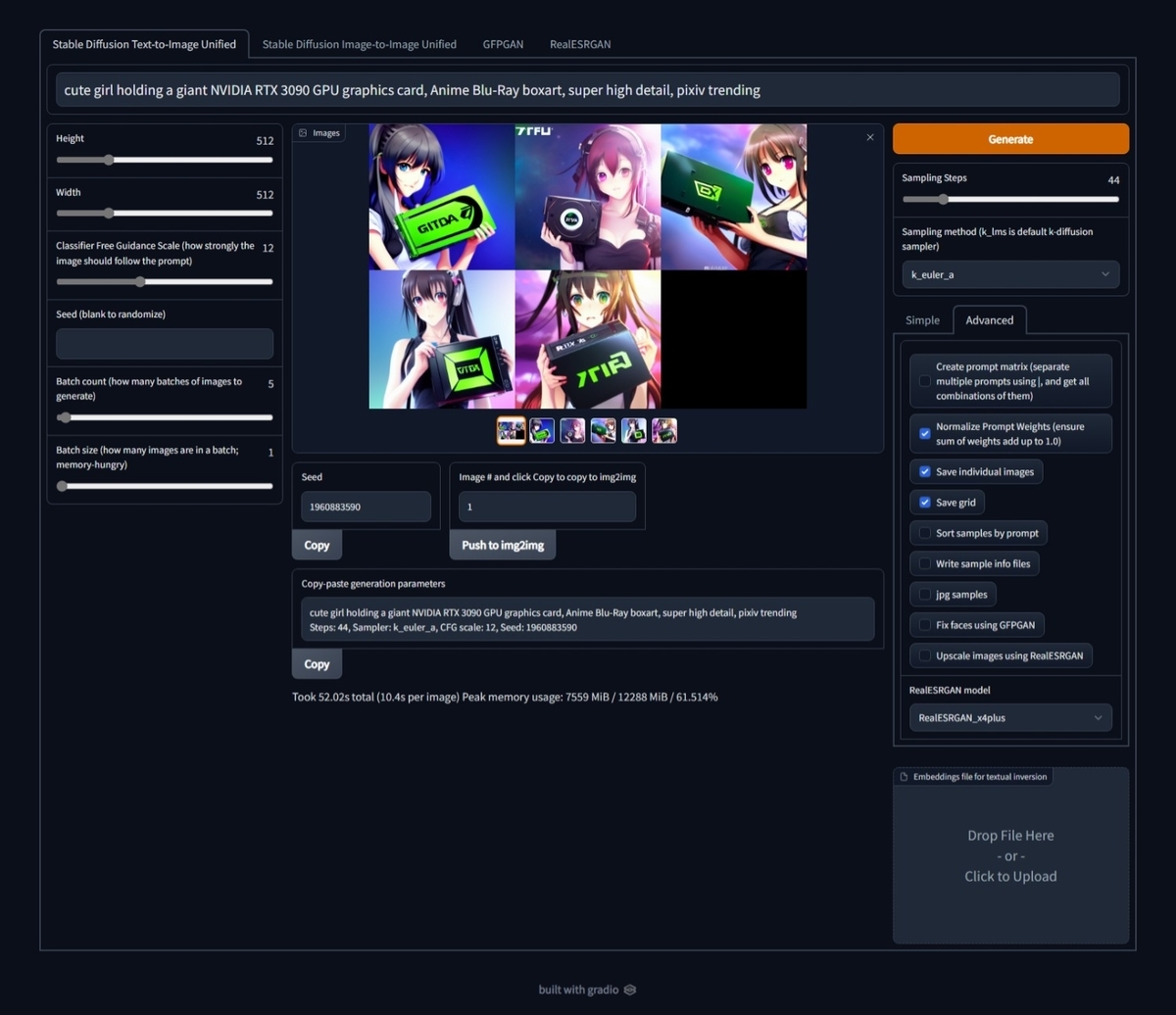
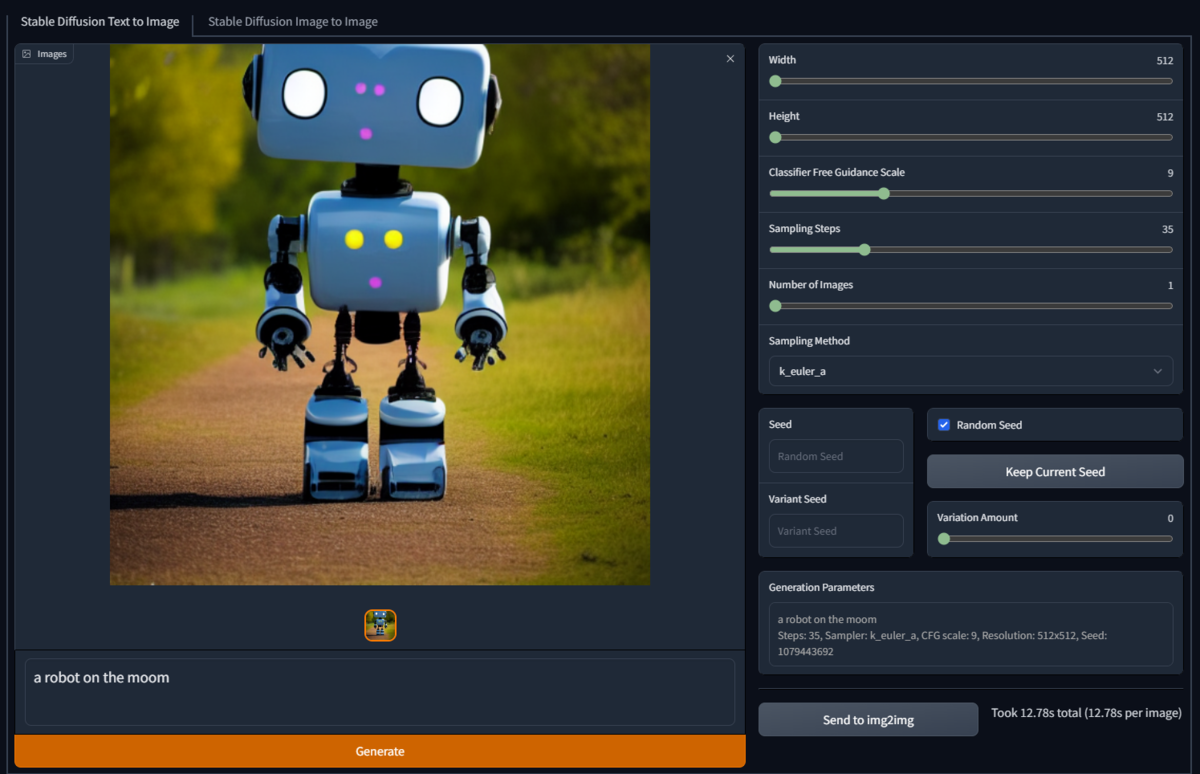
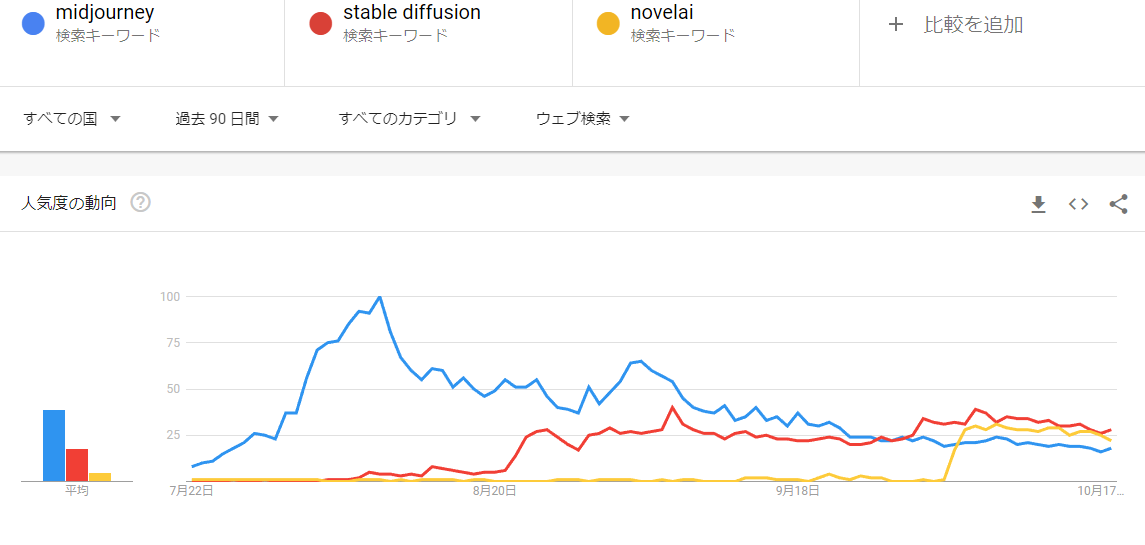
AI画像を生み出す人々
Stable Diffusion、NovelAIDiffusionなど「プロンプトエンジニアリング」によるAI画像生成は、与えた言葉に基づいて芸術と科学(工学)が一体となって画像を作り出す、これまでに無かった新しい芸術的手法と言えよう。
またこの世界では絵師、術師という言葉が使われ始めており、AI画像生成と人の関わりを少し過去の話から未来までを予想してみた。
古来から絵を描く職人を絵師、物作りやプログラムを行う職人は技師と呼ばれている。
Wikipedia によると絵師の歴史は古く律令制下で中務省の「画工司(えだくみのつかさ)」に属し宮殿や寺社の造営に当たって文様や装飾の制作を従事しした職人、平安時代末期以降の、寺社に置かれた絵所に属した画工、浮世絵の原画(下絵)を描くことを職業とする人、そして今は日本の漫画やアニメ、ゲーム風の範疇に入る絵を描く画家・イラストレーターを指す言葉になっている。この世界で用いられる共通言語は絵や写真などの芸術だ。あるいは感性。
技師は産業を支えるあらゆる分野で働く職人を指す言葉だが、ほぼ全ての技術の共通言語は「工学(計算)」だ。特にITやAIはコンピュータ、すなわち自動計算器無しでは成り立たない。
それらに対してAI画像生成のプロンプトを駆使する術師と言う言葉が現れた。プロンプトが言葉で構成されることから術師の共通言語は「言葉」そのものだ。そして言葉で欲しいものを表現する=全体を制御することから映画で言えば監督やプロデューサーに該当する。
古来から三者連携
油絵などが盛んだった時代も、画家(絵師)、画材開発(技師)、どんな絵が欲しいかを要求するディーラーやクライアント(術師)がいた。どんなに優れた画家がいたとしても良い画材が無ければ高度な作品が作れなかっただろうし、自分の描きたいものを自由に描ける一握りの一流画家を除いてディーラーからの依頼に応じて作品が作られてきた。
逆に言えばピカソなどは一人で画家とクライアント、それも飽くなき探究を続ける厳しい顧客を兼ねていたと言えよう。これはジョブスがiPhone等の創造かつ提供側にいたにも関わらず、「私が一番欲しいものを作る!」という世界で一番厳しいユーザーであったのと同じだ。

その様な天才を除き、一般的には三者の協業で絵が作られる。ただし技師は優れた画材を提供する裏方なので表舞台には出てこない。
絵師、技師、術師を全て兼ね備えた偉人も存在する。例としてはレオナルド・ダ・ビンチが挙げられる

AI画像生成での役割
急激に実現したAI画像生成だが、その実現は古来同様に「絵」の学習と理解、「言葉」の学習と理解、それらを実行する「計算」器とエンジニアで成立している。この辺りは各種のAIを説明資料などに詳しく掲載されている。
これからの世界
今後も芸術(感性)と言葉(構成)と工学(計算)を得意とする三者の役割は失われることなく活躍するだろう。ただ、カバーする範囲がお互いに広がり、絵師も技師も術師もAI画像生成が出来る様になった。
絵師は、AI画像生成を優れたアシスタントとして活用するだろう。すでに活用事例も出てきている。絵描きの工程は結構作業量が多く、ベタ塗りなど人間のアシスタントで行っていたものがクリスタなどアプリでワンタッチで塗れる様になったのと同様に手間のかかる作業の軽減に役立つ。絵師:クリエイターにとって理想的な環境が整った現在はむしろ有利だと思う。
技師は引き続きAIの開発に勤しむだろう。開発を重ねる事で2045年に起こると言われているシンギュラリティ(AIが人を超える事態)も遅かれ早かれ到来するだろう。でも依然AIは開発対象に過ぎず技術としての立場は大きく変わらないだろう。一部には絵師として成功する人もいるかもしれないがそれは元々その素養があった例外だと思う。なぜなら技師:エンジニアが愛するのは技術であり芸術ではないからだ(一部例外を除く)。
術師のほとんどは動画生成の方にシフトすると思う。労力を注いでも絵を描き込む熱意は絵師に勝てないし、言葉による指令:スクリプトがより効果なのはシーケンスを有するアニメなどの動画だからだ。その意味でも監督やプロデューサーの立ち位置であり、個人でアニメが作れる時代もすぐに来るだろう。