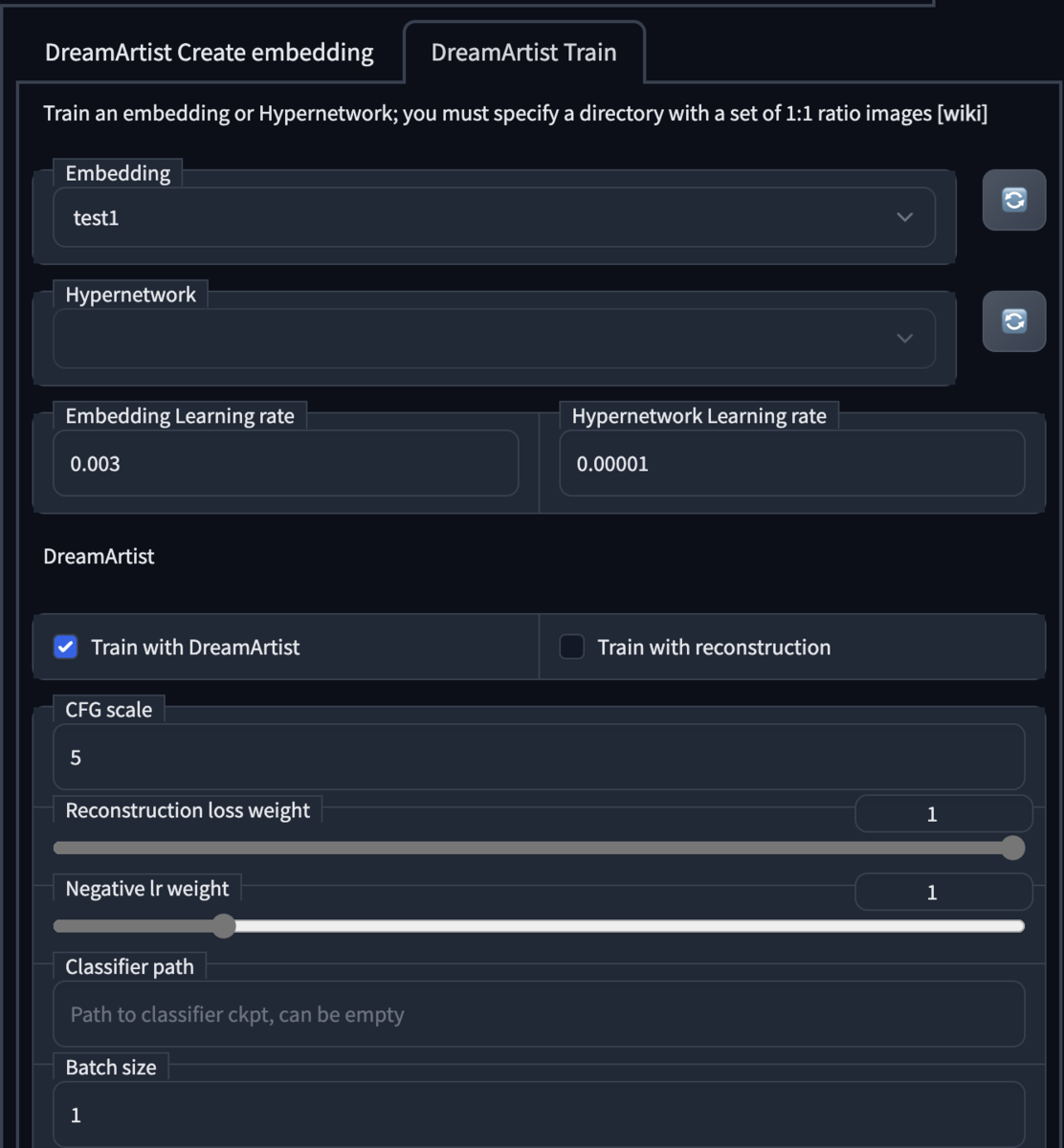
AnythingV3.0、EimisAnimeDiffusion、Evt_V2、Evt-V3、HD-17、デリダ 、Elysium、ACertainModel、ACertainThing、8528d-final
記事の最後に各モデルのダウンロード先と利用方法をまとめた。
ハイレベルな二次元の絵が作成できるモデルが次々と登場している。高杉さんのツイッター によるとAnythingV3.0、EimisAnimeDiffusionはハイパーネットワークの掛かり方からルーツはNovelAIだろうと推察されている。
高杉さんの比較一覧
新登場のモデルの違い
10月までに登場していたアニメモデルは以下の通り
Waifu Diffusion
Trinart Diffusion
NovelAIDiffusion
NovelAIDiffusionが一歩抜きん出ているが、最近のネガティブプロン プトの研究によりWaifuやTrinartもクオリティの高い絵が生成出来る様になってきた。それらに対して最近登場したモデルはいずれもNovelAIDiffusionを参考やベースにしており背景が派手になるようだ。
AnythingV3.0は手の表現が良くなることが多い
EimisAnimeDiffusionはさらに背景が詳細に描かれることが多い
Evt_V2は構図の自由度が上がるようだ
HD-17はHENTAI Diffusionという名前だが反して可愛らしい絵が出る
デリダ モデルはTrinartオリジナルから二次創作に振ったモデルElysiumは強力なモデル、背景描画性などが評価されている(Animeモデル)
ACertainModelは、Laionの悪影響を回避すべくSD1.2ベースで学習
ACertainThingは、上記のAnythingV3.0版
8528d-finalは、852話さんが作った独自モデル
AnythingV3.0、Evt_V2、NovelAIの比較
NovelAI、Evt_V2、Evt_V3の比較
HENTAI Diffusion 17、ダリダ、Waifu1.3の比較
HENTAI Diffusion 17、デリダ モデルの比較
HENTAI Diffusion 17の作例
NovleAI, Anything, Elysiumの比較
NovleAI, Anything, EimisAnimeDiffusion、HD-17、Elysiumの比較
NovleAI, Anything, EimisAnimeDiffusion、HD-17、Elysiumの比較
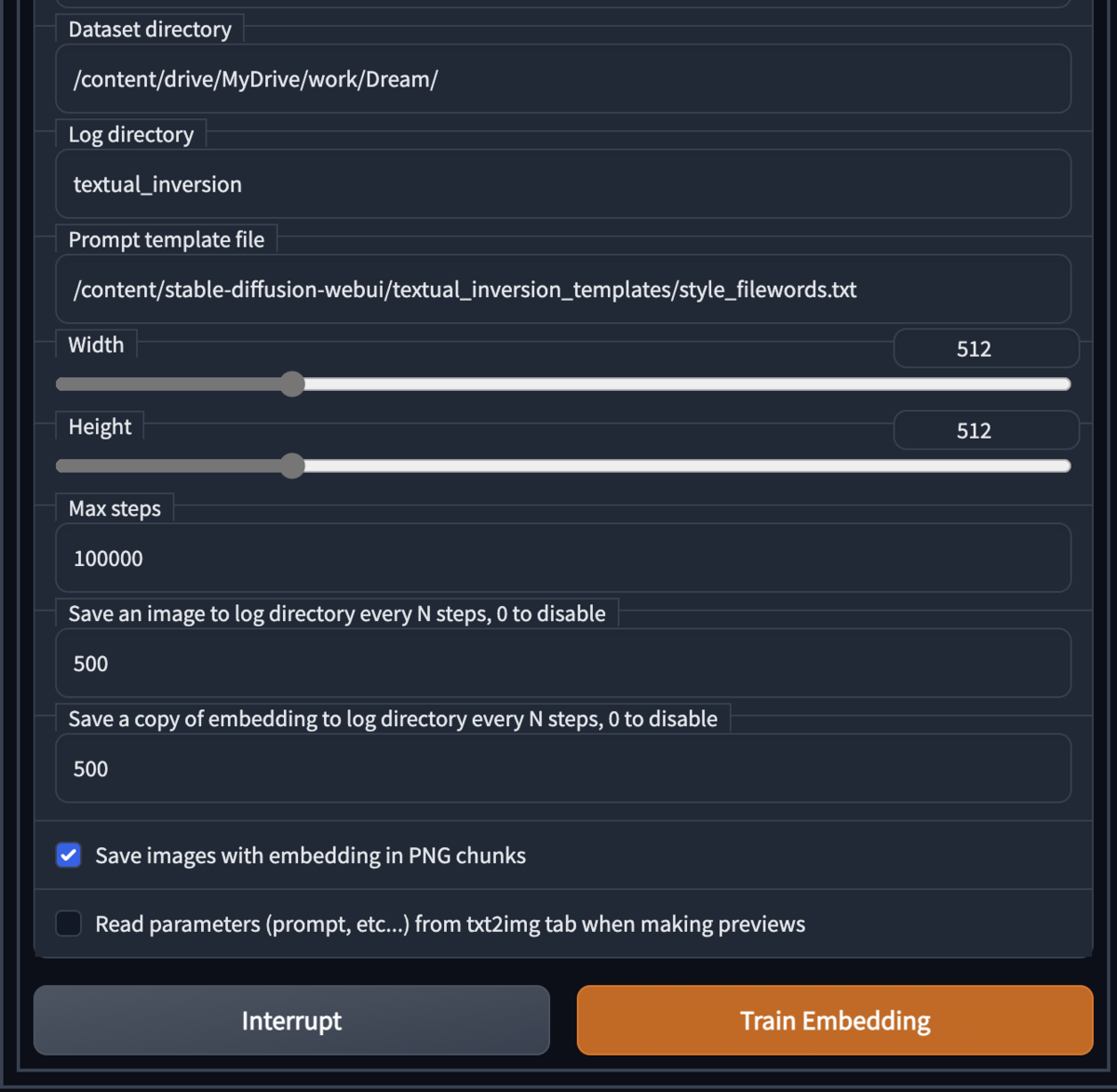
各モデルのcolabでの利用方法
過去記事のcolabノートで実行する例に従って説明する。
programmingforever.hatenablog.com
それぞれの各モデルを所定のGoogleDriveのフォルダに保存する(/modelsなど)
VAEが明記されているものは合わせて保存する
それぞれ記載の内容でノートを修正して実行
アレンジで複数のモデルやVAEを入れると、動的にモデルやVAEが切替可能になる(メモリに注意)
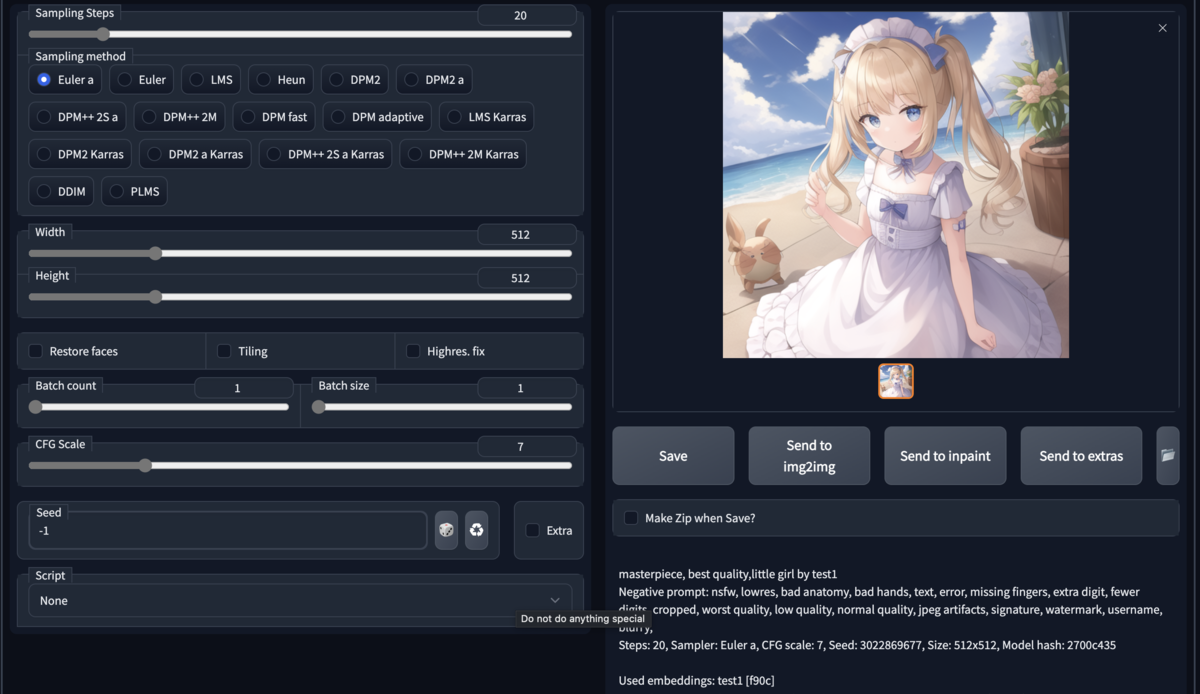
いずれもネガティブプロン プトの利用が望ましい。標準のネガティブプロン プトを記載する。
※標準的なネガティブプロン プト:mutated hands and fingers, text, title, deformed, bad anatomy, disfigured, poorly drawn face, mutation, mutated, extra limb, ugly, poorly drawn hands, missing limb, floating limbs, disconnected limbs, malformed hands, out of focus, long neck, long body
①AnythingV3.0の利用:
Anything-V3.0.ckptと、Anything-V3.0-pruned.ckpt (VAE)をダウンロードする(huggingface.co
colabノート:以下4つのコードセルを順に実行すると指定モデルでAUTOMATIC1111が起動する
# ①GoogleDriveをマウントする
from google.colab import drive
drive.mount('/content/drive')
# ②実行コードのロード (wgetなど不要な3行目以降を割愛)
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd stable-diffusion-webui
# ③GoogleDriveからモデルやVAEをコピー
!cp /content/drive/MyDrive/models/Anything-V3.0.ckpt /content/stable-diffusion-webui/models/Stable-diffusion/
!cp /content/drive/MyDrive/models/Anything-V3.0-pruned.ckpt /content/stable-diffusion-webui/models/VAE/
# ④実行コマンド
!COMMANDLINE_ARGS="--share --gradio-debug --gradio-auth me:qwerty" REQS_FILE="requirements.txt" python launch.py
②EimisAnimeDiffusionの利用:
colabノート:以下4つのコードセルを順に実行すると指定モデルでAUTOMATIC1111が起動する
# ①GoogleDriveをマウントする
from google.colab import drive
drive.mount('/content/drive')
# ②実行コードのロード (wgetなど不要な3行目以降を割愛)
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd stable-diffusion-webui
# ③GoogleDriveからモデルやVAEをコピー
!cp /content/drive/MyDrive/models/EimisAnimeDiffusion_1-0v.ckpt /content/stable-diffusion-webui/models/Stable-diffusion/
# VAEを追加(動的にVAEを切替可能)
!cp /content/drive/MyDrive/models/kl-f8-anime2.ckpt /content/stable-diffusion-webui/models/VAE/
!cp /content/drive/MyDrive/models/Anything-V3.0-pruned.ckptt /content/stable-diffusion-webui/models/VAE/
# ④実行コマンド
!COMMANDLINE_ARGS="--share --gradio-debug --gradio-auth me:qwerty" REQS_FILE="requirements.txt" python launch.py
③Evt_V2 / Evt_V3の利用:
colabノート:以下4つのコードセルを順に実行すると指定モデルでAUTOMATIC1111が起動する
# ①GoogleDriveをマウントする
from google.colab import drive
drive.mount('/content/drive')
# ②実行コードのロード (wgetなど不要な3行目以降を割愛)
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd stable-diffusion-webui
# ③GoogleDriveからモデルやVAEをコピー
!cp /content/drive/MyDrive/models/evt_v2-ema-pruned.ckpt /content/stable-diffusion-webui/models/Stable-diffusion/
# VAEを追加(動的にVAEを切替可能)
!cp /content/drive/MyDrive/models/kl-f8-anime2.ckpt /content/stable-diffusion-webui/models/VAE/
!cp /content/drive/MyDrive/models/Anything-V3.0-pruned.ckpt /content/stable-diffusion-webui/models/VAE/
# ④実行コマンド
!COMMANDLINE_ARGS="--share --gradio-debug --gradio-auth me:qwerty" REQS_FILE="requirements.txt" python launch.py
④HENTAI Diffusion 17の利用:
colabノート:以下4つのコードセルを順に実行すると指定モデルでAUTOMATIC1111が起動する
# ①GoogleDriveをマウントする
from google.colab import drive
drive.mount('/content/drive')
# ②実行コードのロード (wgetなど不要な3行目以降を割愛)
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd stable-diffusion-webui
# ③GoogleDriveからモデルやVAEをコピー
!cp /content/drive/MyDrive/models/HD-17.ckpt /content/stable-diffusion-webui/models/Stable-diffusion/
!cp /content/drive/MyDrive/models/kl-f8-anime2.ckpt /content/stable-diffusion-webui/models/VAE/
# ④実行コマンド
!COMMANDLINE_ARGS="--share --gradio-debug --gradio-auth me:qwerty" REQS_FILE="requirements.txt" python launch.py
※実行時にネガティブプロン プトにダウンロードしたUniversal Negative Prompt Text.txtのテキストをコピペする
⑤デリダ モデルの利用:
モデル:derrida_final.ckptと、VAE:autoencoder_fix_kl-f8-trinart_characters.ckptをダウンロードする(huggingface.co
colabノート:以下4つのコードセルを順に実行すると指定モデルでAUTOMATIC1111が起動する
# ①GoogleDriveをマウントする
from google.colab import drive
drive.mount('/content/drive')
# ②実行コードのロード (wgetなど不要な3行目以降を割愛)
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd stable-diffusion-webui
# ③GoogleDriveからモデルやVAEをコピー
!cp /content/drive/MyDrive/models/derrida_final.ckpt /content/stable-diffusion-webui/models/Stable-diffusion/
!cp /content/drive/MyDrive/models/autoencoder_fix_kl-f8-trinart_characters.ckpt /content/stable-diffusion-webui/models/VAE/
# ④実行コマンド
!COMMANDLINE_ARGS="--share --gradio-debug --gradio-auth me:qwerty" REQS_FILE="requirements.txt" python launch.py
⑥Elysiumの利用:
3つモデルがあり、アニメモデルのElysium_Anime_V2.ckptが良さそうだ。
Elysium_Anime_V1.ckpt
Elysium_Anime_V2.ckpt
Elysium_V1.ckpt
huggingface.co
汎用モデル:Elysium_V1.ckptを使う場合:
Clip skip 1
VAE利用が望ましい: 'vae-ft-mse-840000' from StabilityAI (https://huggingface.co/stabilityai/sd-vae-ft-mse-original/tree/main )
Sampler: DPM++ 2M Karras
ネガティブプロン プト:以下を使用:Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
アニメモデル:Elysium_Anime_V1.ckpt、Elysium_Anime_V2.ckptを使う場合:
Clip skip 1 (2でもよい)
VAE利用が望ましい: 'kl-f8-anime2.ckpt' from Waifu Diffusion (https://huggingface.co/hakurei/waifu-diffusion-v1-4/tree/main/vae )
Sampler: DPM++ 2M Karras
プロンプトに追加:booru
ネガティブプロン プト:以下を使用:Negative prompt: lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
colabノート:以下4つのコードセルを順に実行すると指定モデルでAUTOMATIC1111が起動する
# ①GoogleDriveをマウントする
from google.colab import drive
drive.mount('/content/drive')
# ②実行コードのロード (wgetなど不要な3行目以降を割愛)
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd stable-diffusion-webui
# ③GoogleDriveからモデルやVAEをコピー
!cp /content/drive/MyDrive/models/Elysium_Anime_V2.ckpt/content/stable-diffusion-webui/models/Stable-diffusion/
!cp /content/drive/MyDrive/models/kl-f8-anime2.ckpt /content/stable-diffusion-webui/models/VAE/
# ④実行コマンド
!COMMANDLINE_ARGS="--share --gradio-debug --gradio-auth me:qwerty" REQS_FILE="requirements.txt" python launch.py
⑦ACertainModelの利用:
colabノート:以下4つのコードセルを順に実行すると指定モデルでAUTOMATIC1111が起動する
# ①GoogleDriveをマウントする
from google.colab import drive
drive.mount('/content/drive')
# ②実行コードのロード (wgetなど不要な3行目以降を割愛)
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd stable-diffusion-webui
# ③GoogleDriveからモデルやVAEをコピー
!cp /content/drive/MyDrive/models/ACertainModel.ckpt /content/stable-diffusion-webui/models/Stable-diffusion/
!cp /content/drive/MyDrive/models/animevae.pt /content/stable-diffusion-webui/models/VAE/
# ④実行コマンド
!COMMANDLINE_ARGS="--share --gradio-debug --gradio-auth me:qwerty" REQS_FILE="requirements.txt" python launch.py
⑧ACertainThingの利用:
colabノート:以下4つのコードセルを順に実行すると指定モデルでAUTOMATIC1111が起動する
# ①GoogleDriveをマウントする
from google.colab import drive
drive.mount('/content/drive')
# ②実行コードのロード (wgetなど不要な3行目以降を割愛)
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd stable-diffusion-webui
# ③GoogleDriveからモデルやVAEをコピー
!cp /content/drive/MyDrive/models/ACertainThing.ckpt /content/stable-diffusion-webui/models/Stable-diffusion/
!cp /content/drive/MyDrive/models/animevae.pt /content/stable-diffusion-webui/models/VAE/
# ④実行コマンド
!COMMANDLINE_ARGS="--share --gradio-debug --gradio-auth me:qwerty" REQS_FILE="requirements.txt" python launch.py
⑨8528d-finalの利用:
8528d-final.ckptをダウンロードしてGoogleDriveに保存する
huggingface.co
colabノート:以下4つのコードセルを順に実行すると指定モデルでAUTOMATIC1111が起動する
# ①GoogleDriveをマウントする
from google.colab import drive
drive.mount('/content/drive')
# ②実行コードのロード (wgetなど不要な3行目以降を割愛)
!git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
%cd stable-diffusion-webui
# ③GoogleDriveからモデルをコピー
!cp /content/drive/MyDrive/models/8528d-final.ckpt /content/stable-diffusion-webui/models/Stable-diffusion/
# ④実行コマンド
!COMMANDLINE_ARGS="--share --gradio-debug --gradio-auth me:qwerty" REQS_FILE="requirements.txt" python launch.py
※実行に際してはDLサイトにある説明を参考