1枚の絵だけで学習するDreamArtist
複数枚の絵で学習させるDreamBoothに対して1枚の絵だけで学習できるDreamArtistが登場した。AUTOMATIC1111で使えるとのことなので早速Google colabで試してみた。
DreamArtistとは
必要なファイルをDL出来るサイトは以下の通り。
DreamArtistは、1つのトレーニング画像でコンテンツとスタイルを学習し、制御性の高い多様な高品質の画像を生成します。 DreamArtist の埋め込みは、追加の説明や 2 つの学習した埋め込みと簡単に組み合わせることができます。
イメージ図。元画像のキャラが再現できている。




Texture Inversion, DreamBooth,との比較(いずれも学習は1枚のみ)

Imagicとの違い
同様に1枚の絵だけで学習するツールとしてImagicがある。下に実証記事を示す。
programmingforever.hatenablog.com
Imagicは絵とプロンプトをセットで学習させる方式で、絵のレイアウトもほぼ固定となる(プロンプトで指定した部位は異なる)。またプロンプトとのセットで都度モデルを作る方式なのでバリエーションの作業効率は悪く、DreamArtistの方が総合的に優れていると判断する。
実証手順
※記事の最後に学習用と実行用のノートをまとめている。
①colabでAUTOMATIC1111を使う準備
まずcolabでAUTOMATIC1111を動かす準備をする。モデルは何でも良いが今回はAnything-V3.0を使った。利用方法の解説記事はこちら。
programmingforever.hatenablog.com
Anything-V3.0は下記のサイトなどからckptとVAEをダウンロードする。
ckptとVAE.ptのモデルの利用方法は下記参照(ファイル名を合わせる)。
programmingforever.hatenablog.com
②ノートブックを修正して実行
colabでAUTOMATIC1111を起動すると、エクステンションタブで色々と選べる様になっており、DreamArtistも存在している。しかしここで選択してもcolabの場合はエラーになってしまうので使えない。

そこでノートブックを編集する。先ほども例に挙げたノートブックに、エクステンションのダウンロードを追加する。例に示したノートブックを利用する場合、下記の様にコードセルを修正する。
追記は、DreamArtistのGitHubから、colabのエクステンションフォルダにロードするコマンドのみ。
# %cd stable-diffusion-webui !git pull
↓
# %cd stable-diffusion-webui !git pull !git clone https://github.com/7eu7d7/DreamArtist-sd-webui-extension.git /content/stable-diffusion-webui/extensions/DreamArtist
これで順番にコードセルを最後まで実行すると、DreamArtistのタブが出ているのが確認できる。
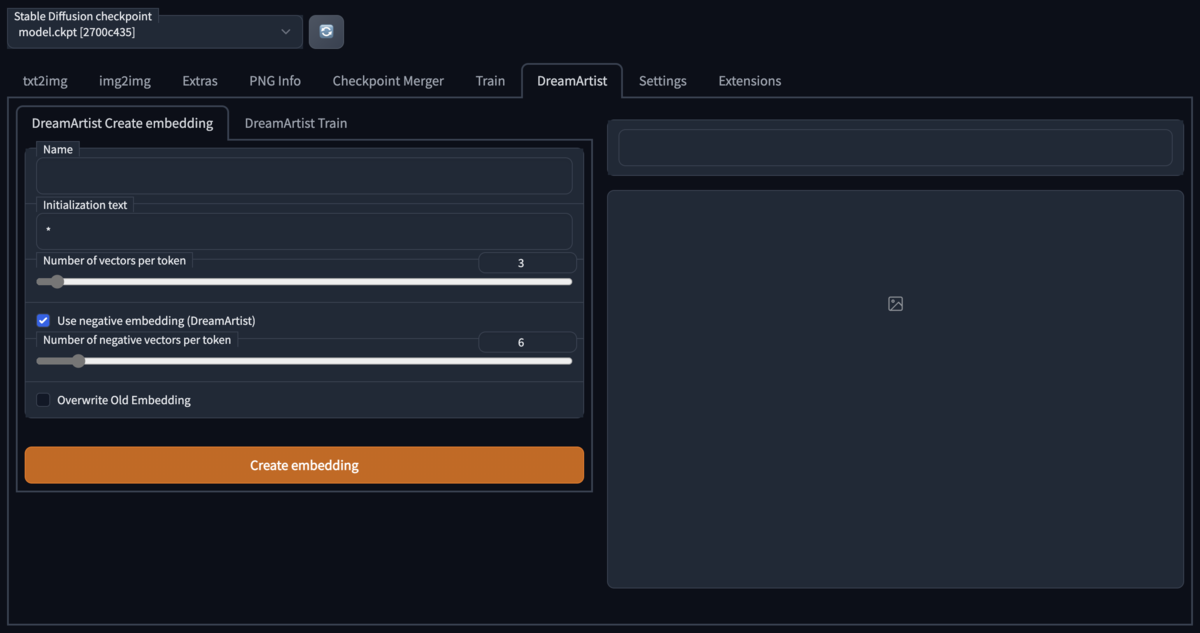
③トレーニング(1)
まずモデルとなる絵を1枚用意する。今回は下記を使用する。

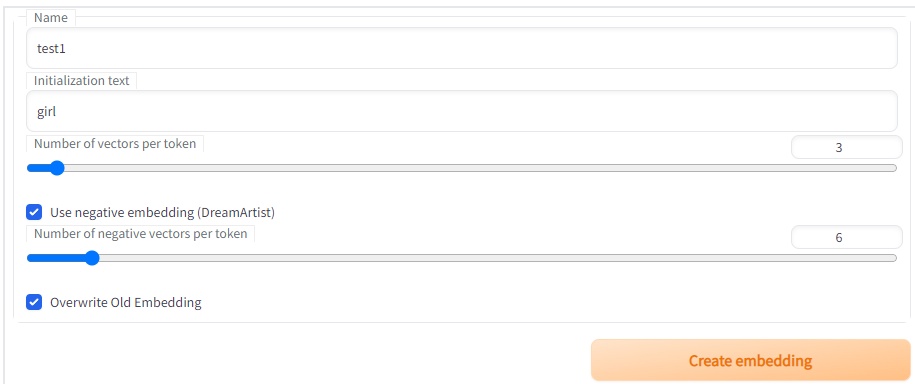
次にプロンプトとネガティブプロンプトの埋め込みを inTab で作成する。名前を適当に付けて(この例ではtest1)、修飾対象を記載し(この例ではgirl)、後は図の通りにセットして「create embedding」を押す。
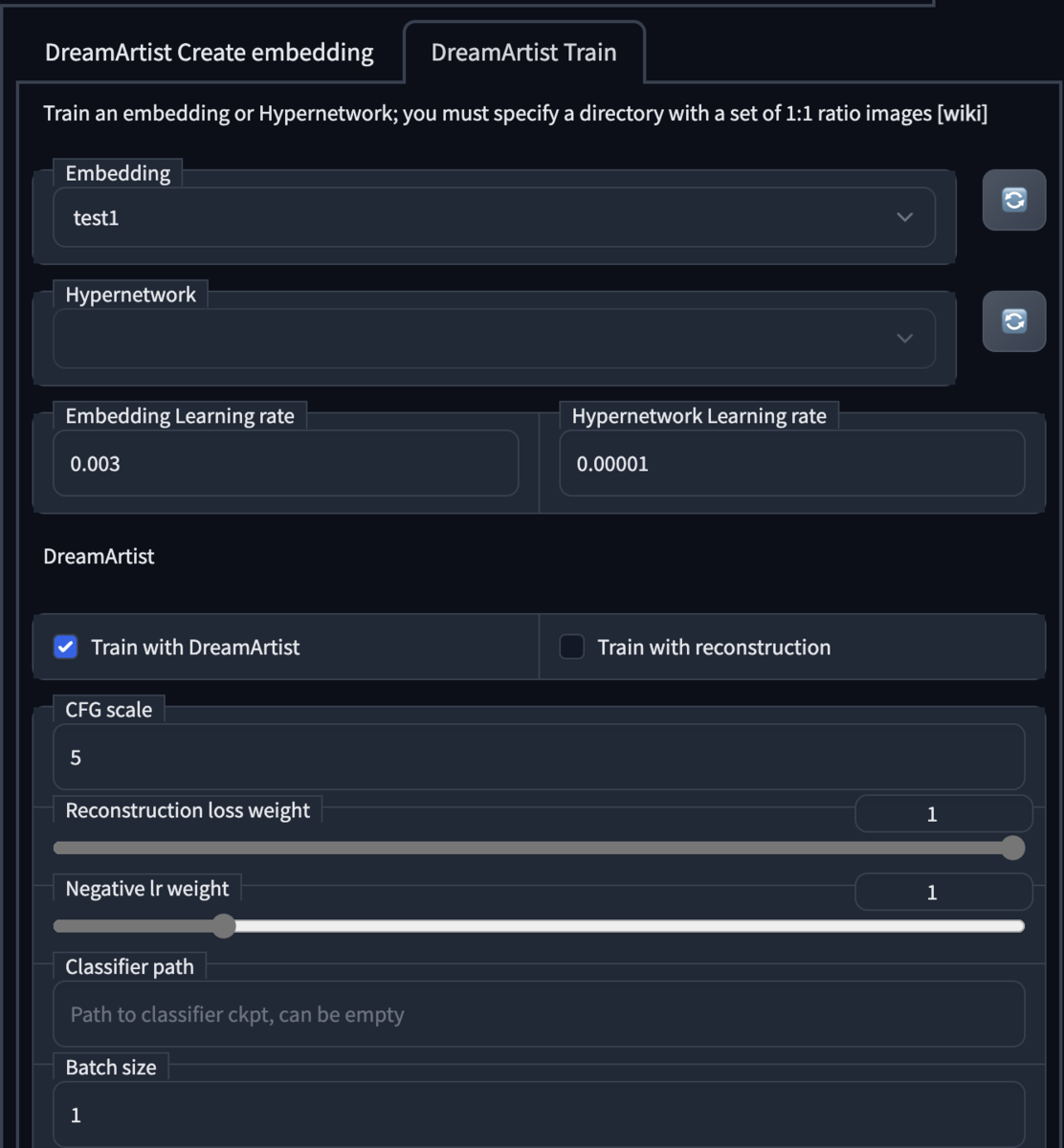
④トレーニング(2)
引き続き下記を順に設定して訓練を開始する。
- まず「DreamArtist train」のタブを選ぶ
- Embeddingに先ほど付けた名前を入力(test1など)
- Embedding learning rate:0.003
- Hypernetwork leaning rate:0.00001
- Train with DreamArtistにチェック
- Train with Reconstructionのチェックを外す(注意!)
- Dataset directoryを指定する:例:/content/drive/MyDrive/work/Dream/
- その指定したフォルダに先ほどの画像を1枚入れる
- Max stepsに学習させたいステップ数を入れる。500ステップで10分程度。例えば1000など。ステップ数が増えればより精度が高まる(と思われる)。長すぎた場合は中断も可能(途中まで行った学習は残る)。
- 「Train Embedding」ボタンクリックで訓練開始
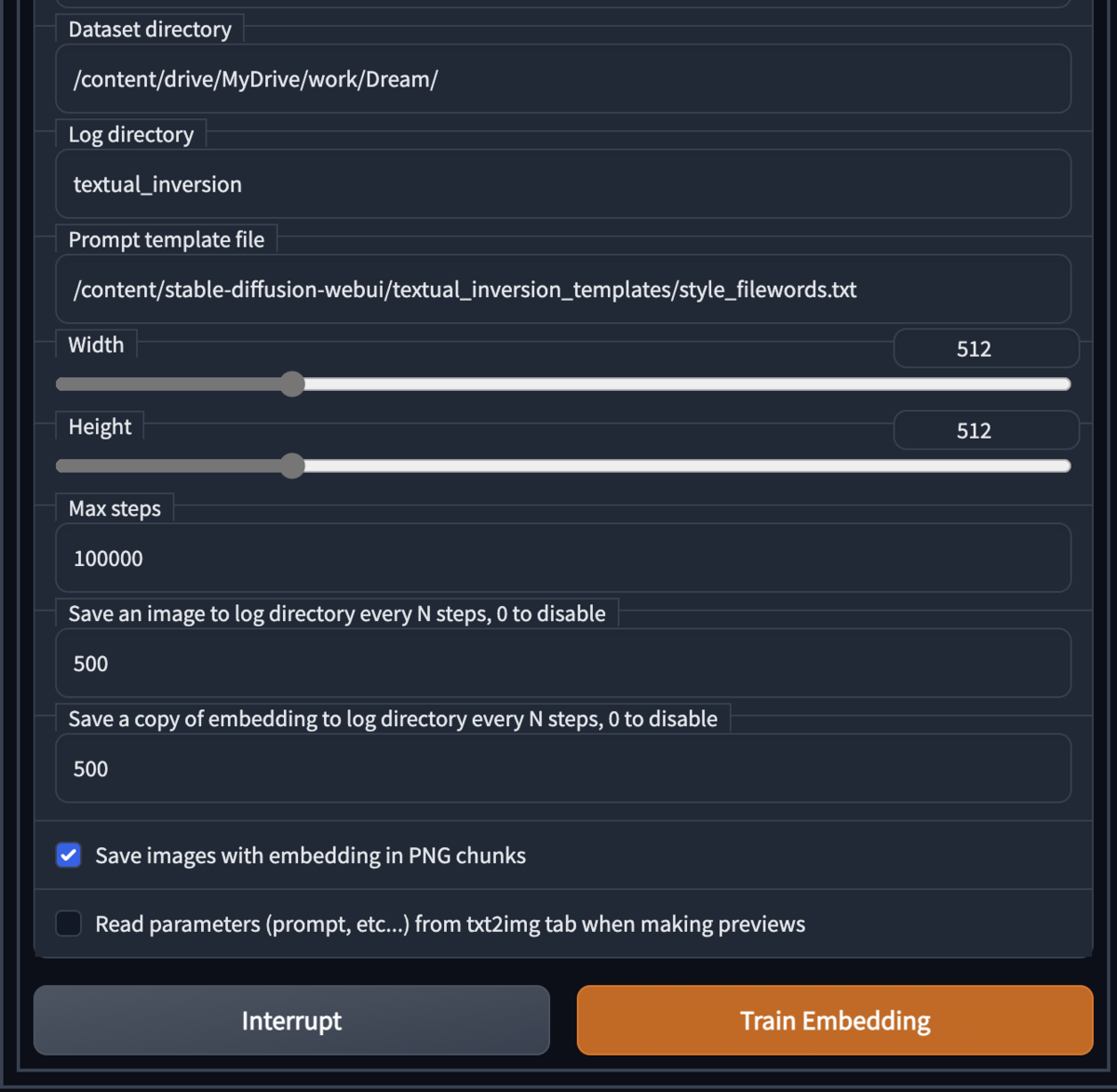
これでDreamArtistの学習は完了。
④実行
実行は普段通りのtxt2imgなどを行うと自動的に反映される。なおプロンプトに指定した「girl」と「by test1」が必要。すると図の様に同じキャラが描かれる。生成メッセージを見るとDreamArtistで訓練したEmbeddingを使っているメッセージが出ている(一番最後の行)。
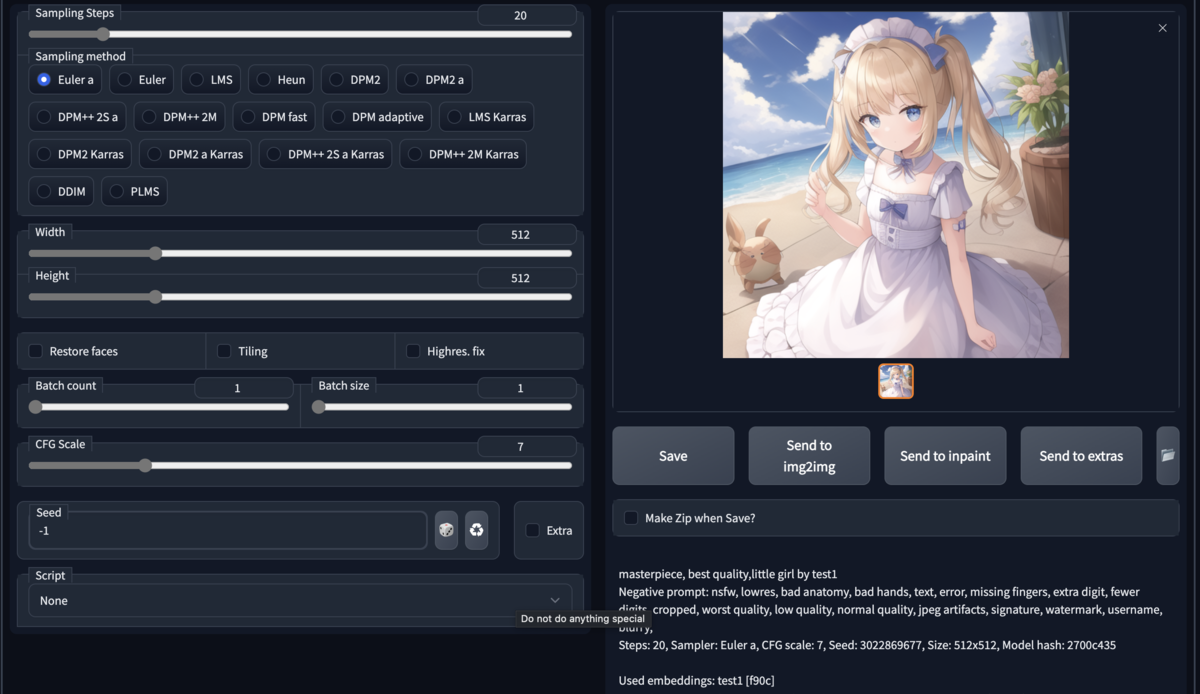
生成された絵を掲載する。


学習データの保存
DreamArtinstは、指定したname(ファイル名)とinitialization text(girlなどの汎用名称)を入れて学習すると、/content/stable-diffusion-webui/embeddings/に、「ファイル名.pt」と「ファイル名-neg.pt」の2つのTextual Inversion方式のファイルが作られる。
※例:name(ファイル名)がtest2の場合、test2.ptとtest2-neg.ptの2つが作られる。
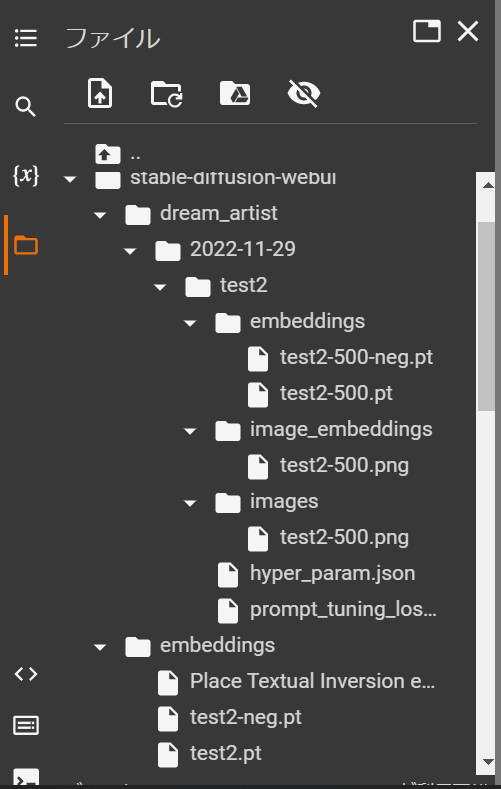
学習データの保存:
保存は、/content/stable-diffusion-webui/embeddings/フォルダに入っている、「ファイル名.pt」と「ファイル名-neg.pt」を保存する。
学習データの利用:
利用時はTextual Inversion同様に、/content/stable-diffusion-webui/embeddings/フォルダに「ファイル名.pt」と「ファイル名-neg.pt」を格納する。
プロンプトにname(ファイル名)を入力すると作動する。正しく使用された場合はログに「Used embeddings: ファイル名 [****]の表記が出る。
(例:initialization text:girl、name(ファイル名):test2で学習した場合:「girl」と「test2」が必要)
まとめ:ノート①DreamAction学習用:
# ①GoogleDriveをマウント
from google.colab import drive
drive.mount('/content/drive')
# ②AUTOMATIC1111をclone、DreamActionをclone !git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui %cd stable-diffusion-webui !git clone https://github.com/7eu7d7/DreamArtist-sd-webui-extension.git /content/stable-diffusion-webui/extensions/DreamArtist
# ③GoogleDriveからモデルとVAEを所定の場所にコピー(Anything3.0) !cp /content/drive/MyDrive/models/Anything-V3.0.ckpt /content/stable-diffusion-webui/models/Stable-diffusion/ !cp /content/drive/MyDrive/models/Anything-V3.0-pruned.ckpt /content/stable-diffusion-webui/models/VAE/
# ④推論実行 !COMMANDLINE_ARGS="--share --gradio-debug --gradio-auth me:qwerty" REQS_FILE="requirements.txt" python launch.py
まとめ:ノート②DreamActionのTI利用:
# ①GoogleDriveをマウント
from google.colab import drive
drive.mount('/content/drive')
# ②AUTOMATIC1111をclone !git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui %cd stable-diffusion-webui
# ③GoogleDriveからモデル、VAE、学習データを所定の場所にコピー(Anything3.0) # 学習データは/content/drive/MyDrive/work/embeddings/にあるものとする !cp /content/drive/MyDrive/models/Anything-V3.0.ckpt /content/stable-diffusion-webui/models/Stable-diffusion/ !cp /content/drive/MyDrive/models/Anything-V3.0-pruned.ckpt /content/stable-diffusion-webui/models/VAE/ !cp -r /content/drive/MyDrive/work/embeddings/ /content/stable-diffusion-webui/
# ④推論実行 !COMMANDLINE_ARGS="--share --gradio-debug --gradio-auth me:qwerty" REQS_FILE="requirements.txt" python launch.py