Google colabとは
Google colabは、Google社が機械学習の教育や研究用で提供する、インストール不要でPythonや機械学習・深層学習の環境をすぐに構築出来る無料のサービス。CPU及びGPU(1回12時間)の環境が利用可能。基本的に無料で使えるが、高速なGPUが使える有料サービスもある。
Google colabでAI画像生成
MidJourneyなどAI画像生成を使うにはwebサービスを使うのが一般的だ。それに対してStable Diffusion は研究成果一式をオープンにして誰でも自由にローカルPCあるいはクラウド上で画像生成が行える様にした。これを受けて爆発的に世界中で研究や開発が加速している。
但しローカル環境で画像生成する場合はそれなりのGPUとメモリを積んだPCで無ければ実行は難しい。2022年現在で理想的なPCを構築しようとするとかなりの投資が必要になるだろう。
その解決策として、ローカルPCではなくクラウド上で同様に実行できるGoogle colab を利用する方法がある。利用の都度ノートブックと称する開発環境を新たに作って使い、終われば破棄する利用方法なので、設定を間違えたらどうしよう、動かなくなったらどうしよう、という不安からも解放される。
そこで本記事では、Google colabにStable Diffusionをインストールして使う手順を一式解説する。作業量はわずかで画像生成できるまで20分程度で完了する。必要なPythonのプログラムコードが全く分からなくてもコピペすれば大丈夫なので気軽にトライ出来る。
txt2imgに加えてimg2img、Waifu Diffusionの利用方法も記載
今回の記事は長文になってしまったが、最初に標準のStable Diffusionを用いたプロンプトからの画像生成方法をまとめた。次に元画像+プロンプトで生成するimg2imgの画像生成、3番目には二次元生成で話題のWaifu Diffusionの画像生成の手順を示した。2番目以降は1とほぼ同じ手順なので、いずれも簡単に試せるだろう。
colabに慣れたらAUTOMATIC1111を使おう
今回の記事はcolabを初めて使う方がcolabのコマンドプロンプトで画像を生成できるところまでを説明している。ただMidJourneyやDreamStudioと比較すると画像生成ツールとしては正直使いづらい。そこでcolabに慣れたら、次はcolabでweb上でのユーザーインターフェースが使える、Stable Diffusion web AIのAUTOMATIC1111の利用をお勧めする。
MidJourneyやDreamStuidoの様なwebのユーザーインターフェースが使えて、多彩な加工機能(ほぼ全部盛り)を楽しめる。普通の絵の作成でも邪魔をしてくるNSFWフィルターもOFFできる。
programmingforever.hatenablog.com
ただしいきなりcolabでAUTOMATIC1111を使うのはやや難しいので、とりあえず今回の記事(実例1だけでもOK)を先に経験することをお勧めする。
【実例1】txt2img:プロンプトから生成
それでは最初に、プロンプトからAI画像を生成するAI画像生成環境を構築する手順を一式解説する。Stable Diffusionを用いる場合の標準的な利用方法で、MidJourneyやDreamStudioの様なwebサービスを自分の手で構築できる。
導入ステップ①:Googleアカウント準備
※Googleのアカウントがあればスキップ。
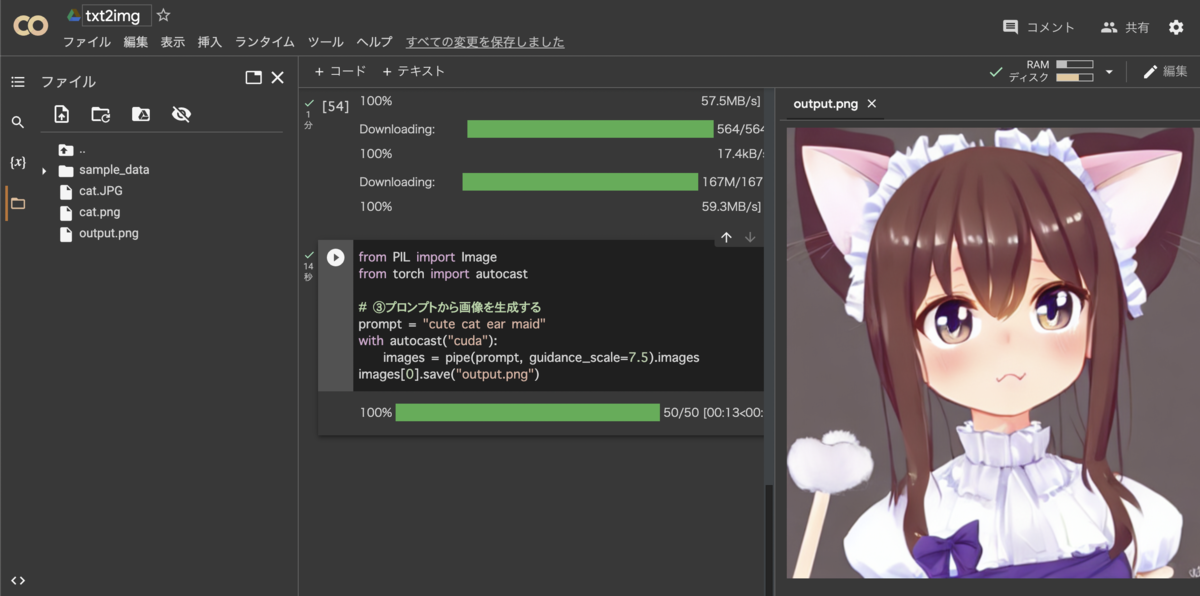
下の様な画面が表示されたらOK。すでにPythonなどの環境が揃っている。
このサイトで新規ノートブックを作って作業を行っていく。
導入ステップ②:Hugging Faceアカウント登録
Stable Diffusionを利用するにはHugging Faceのアカウントを取得し、アクセストークンを発行する。Hugging Faceのアカウントがあればスキップ。
1.Hugging FaceのURLにアクセス
2.画面のsing upをクリック
3.入力したeメールに届いた承認リンクをクリックし、ユーザー名などの情報を入力。ユーザー名はユニークなので先に使われている場合は使えない。全て完了すると完了画面が表示される。
導入ステップ③:Hugging Faceのトークン発行
- 画面右上の黄色い丸をクリック
- 出てきたリストの中のSettingsをクリック
- さらにリストの中のAccess Tokenをクリックすると下記の画面が出るので「New Token」をクリック
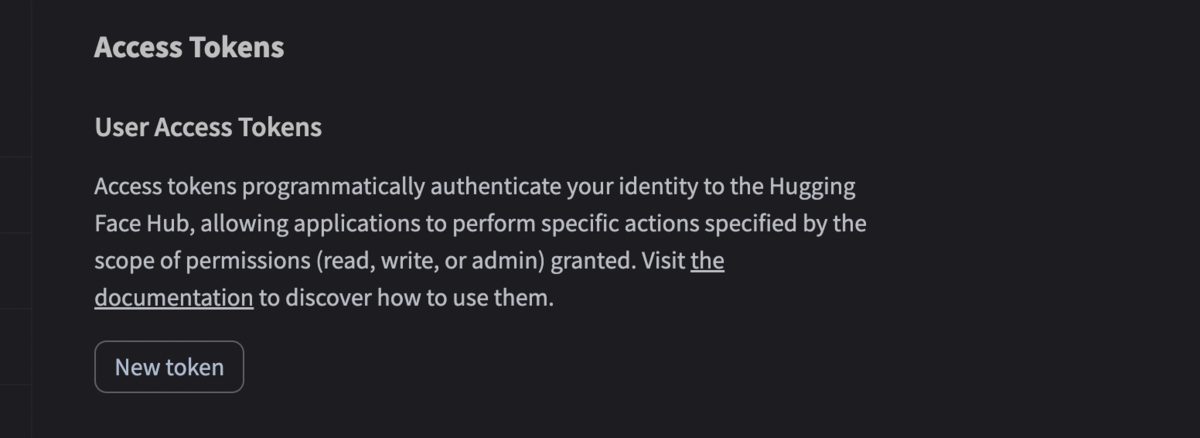
4.出てきた下の画面でトークンの名前(適当でOK)、「read」を選択した上で「Generate Token」をクリック
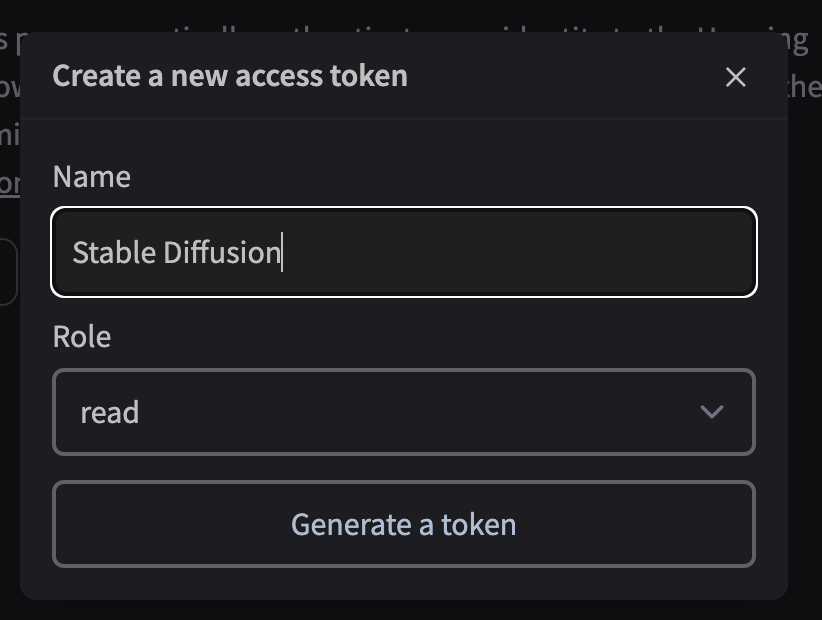
5.出てきた下の画面の右側にある四角いアイコンをクリックするとトークンがコピーされる
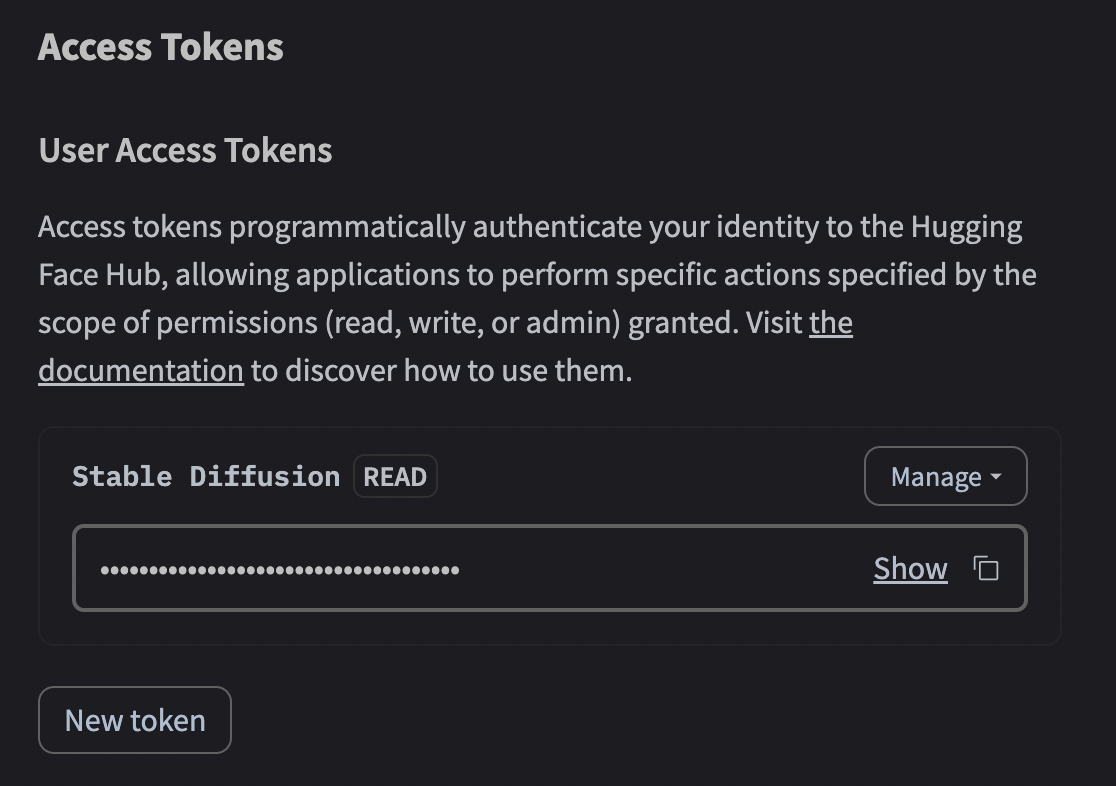
どこかメモにコピーしてもよいし、いつでもコピーは行える。
導入ステップ④:Google colabのGPU設定
- Google colabのURLにアクセス
2.初期画面に出てくる「ノートブックを新規作成」をクリック(あるいはメニューで選択)
3.メニューの「編集」ー「設定」をクリック
4.出てきた設定画面でハードウェアアクセラレータを「GPU」に変更
これから使うnotebookは、Stable Diffusion実行時にGPUを使うためハードウェアアクセラレータを「GPU」に設定する。設定後「保存」を押すと、これ以降はGPUが使える。無料のフリープランで十分実行出来るが、過負荷などで実行割り当てしてもらえない場合は、有料プランのColab Pro(月額1,000円程度)の選択を考えてもよい。
これでColabの初期設定は完了。
導入ステップ⑤:txt2imgのStable Diffusionの設定を書く
続いてStable Diffusionを使うべく、4つのPythonプログラムを書いて実行する。とは言ってもプログラムの中身が分からなくてもコピペで実行できる。
4つのPythonプログラム
以下を書いて順に実行することでAI画像生成が行える。
- ①Stable Diffusionパッケージをインストール
- ②Hugging Faceへのアクセストークンをトークン変数に格納
- ③StableDiffusionパイプラインを準備する
- ④プロンプトを与えて画像を生成する
①Stable Diffusionパッケージをインストール
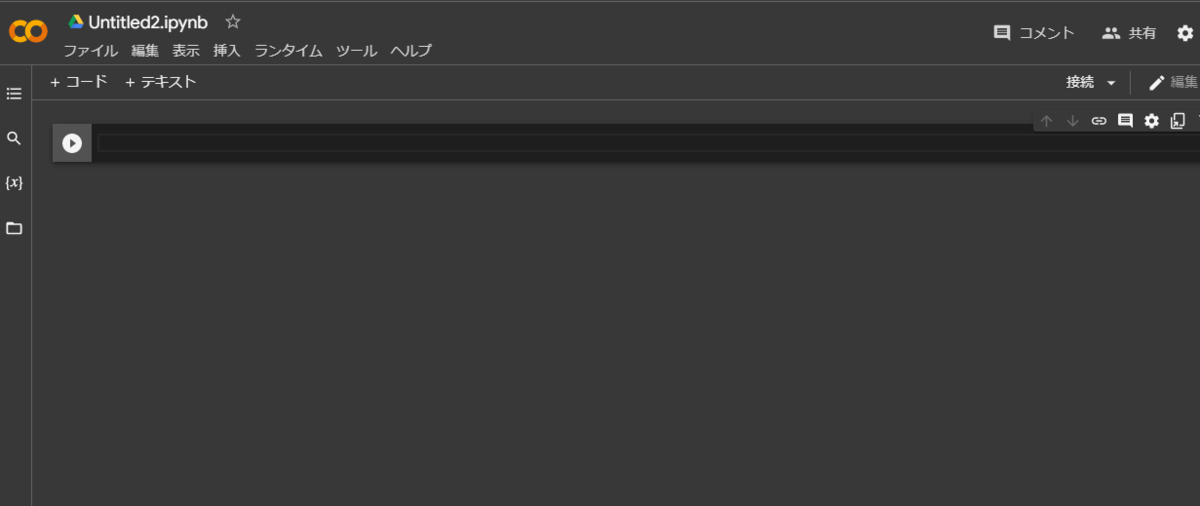
上の様にGoogle colabでノートブックを新規作成するとカーソル待ち状態にあるので、そこに下記のコードをコピペする。
# ①Stable Diffusionパッケージをインストール !pip install diffusers==0.3.0 transformers scipy ftfy
左にある矢印ボタンをクリックするとコードを実行するが、とりあえず先に全コードを入力する。
コード入力だが、プログラムの機能(ブロック)毎にコードを分けて入力すると、各ブロック単位で個別に実行が可能になる。今回で言えば④のコードを実行する度にAI画像が生成される訳だが、もし全コードを一つのブロックに入れてしまうと、①や②の部分で時間や負荷がかかる無駄が生じてしまう。これを実行単位の切り分けで回避出来る訳だ。またデバッグにも便利だ。
では2番目となる別のコード入力用ブロックに入力すべく、現在のコードが入った囲みの最下部にマウスを移動すると「+コード」「+テキスト」の表記が現れるので、「+コード」をクリックする。
これで新しく生成されたコード入力様ブロックに次のコードを入力出来る様になった。
②Hugging Faceへのアクセストークンをトークン変数に格納
下のコードをコピペするが、<HugginFace HubのサイトでコピーしたAccess Tokenをここに入れる>>の部位に、導入ステップ③でコピーした、アクセストークンを入れる("hf_******"と書いてあるもの)。注:<>の記号は不要。
# ②Hugging Faceへのアクセストークンをトークン変数に格納 MyTOKEN="<HugginFace HubのサイトでコピーしたAccess Tokenをここに入れる>"
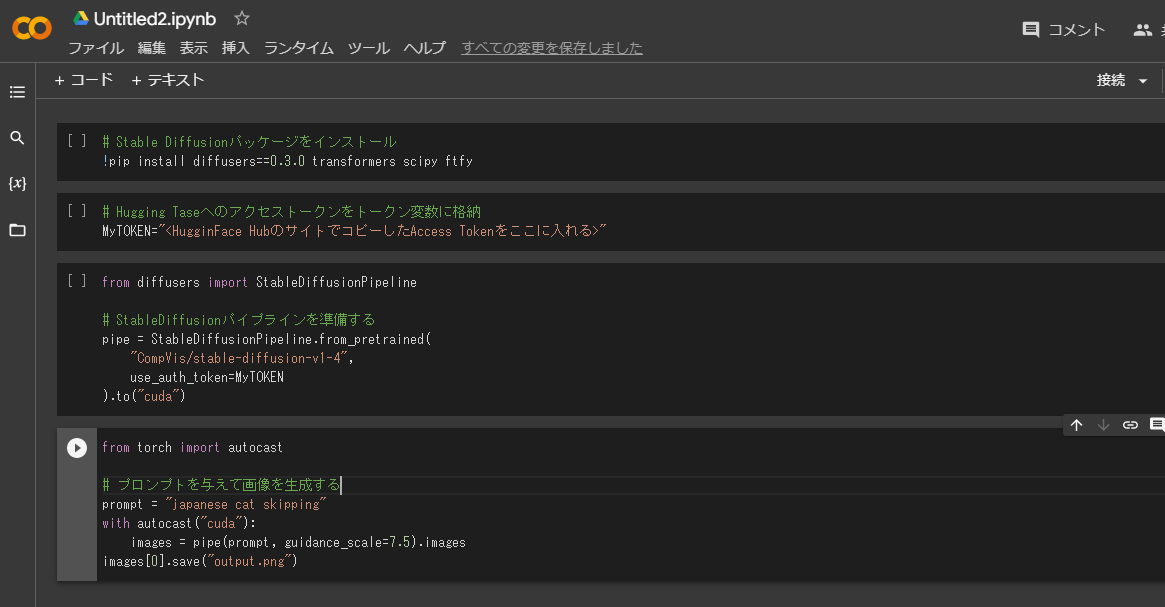
③StableDiffusionパイプラインを準備する
同様に3番めのコードブロックに下記をコピペする。
# ③StableDiffusionパイプラインを準備する
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
use_auth_token=MyTOKEN
).to("cuda")
④プロンプトを与えて画像を生成する
同じく4番目のコードブロックに下記をコピペする。プロンプトは「japanese girl」、日本の少女にしたが、何でも構わない。
# ④プロンプトを与えて画像を生成する
from torch import autocast
prompt = "japanese girl"
with autocast("cuda"):
images = pipe(prompt, guidance_scale=7.5).images
images[0].save("output.png")
ここまで入力した状態。
※画面のアクセストークンは例なので自分のアクセストークンを正しく入力のこと
導入ステップ⑥:txt2imgを実行
それでは各ブロックのPythonコードを最初から順に実行しよう。一番上のブロックにマウスを移動させると、そのブロックの左に白い矢印が現れるのでクリック。するとStable Diffusionパッケージのインストールが始まる(10秒程度)。ずらずらと作業を示すコードが現れ、完了したら矢印の左に緑色のチェックマークが入る。
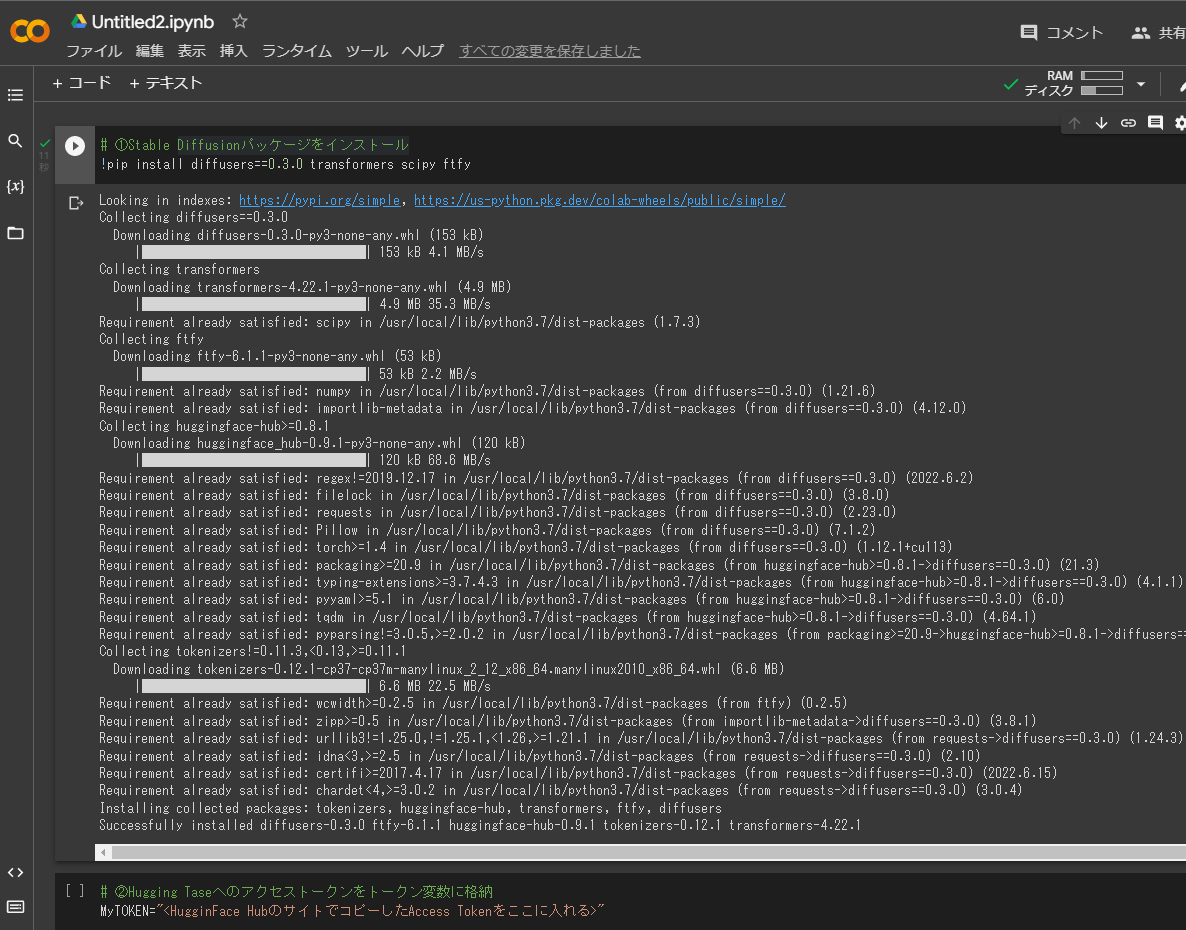
次に2番目のHugging Taseへのアクセストークンをトークン変数に格納、のブロックに移動した同様に白い矢印をクリック。これはすぐに完了する。
同じ様に3番目のStableDiffusionパイプラインを準備する、をクリックするとかなり時間がかかる(数分)。しばし待とう。
全て準備が整ったので、最後の4番目のプロンプトの白い矢印をクリックすれば15秒程度で画像が生成される。ここからはMidJourneyなどと同じなので、お気に入りの絵ができるまで何度も同じプロンプトを実行させたり、プロンプトも色々変更したりなど試せる。
但し生成の都度、前に作った生成ファイルが消えるので、お気に入りのものはダウンロードが必要。
画像確認
画面の一番左側にあるフォルダアイコンをクリックして、「output.png」をクリックすると生成した画像が見える。
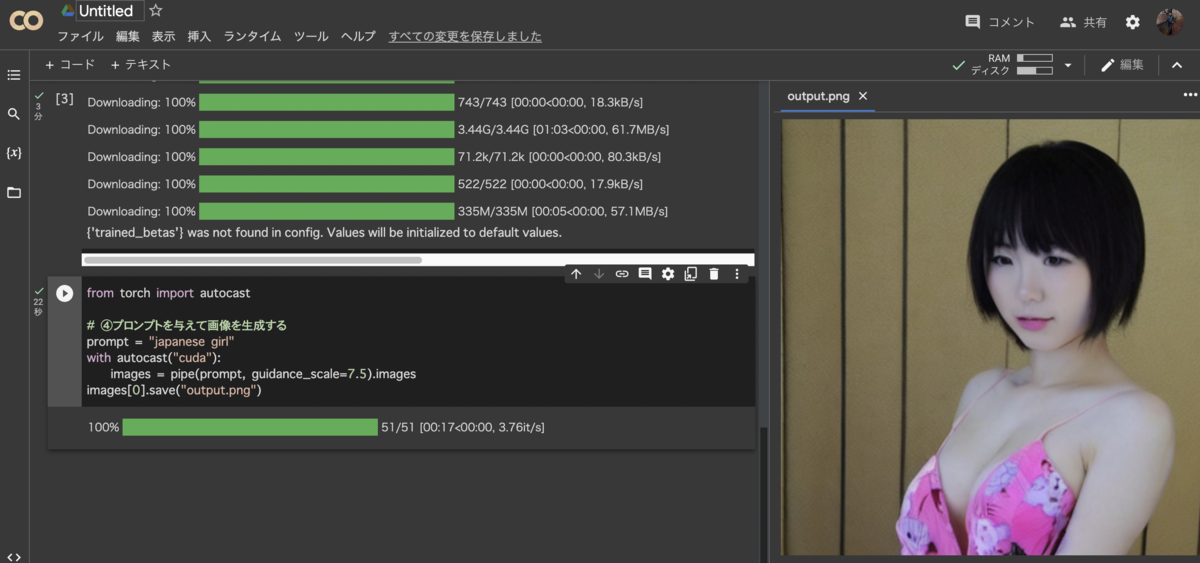
注意点として、作業完了後はGoogle colabで生成したファイルが全て消失するので、気に入った作品はダウンロードを忘れない様に。写真画像の右上にある3本線のアイコンをクリックしてダウンロードを選択。
エラーが出た場合の対策
- 設定の「GPU」を忘れていないか
- アクセスキーの間違いや破損。簡単なのでアクセスキーの作り直しがお勧め
- どこかにエラーがあった際は、最初のコードから全て再実行させること
作例


【実例2】img2img:画像を基に画像生成させる
手書きで絵の構成などのプロットを与え、そこにプロンプトで指示を加えて生成する、img2imgの手法がある。これも前記したtxt2imgの導入ステップ④から⑥とほぼ同じ手順で実行出来る。
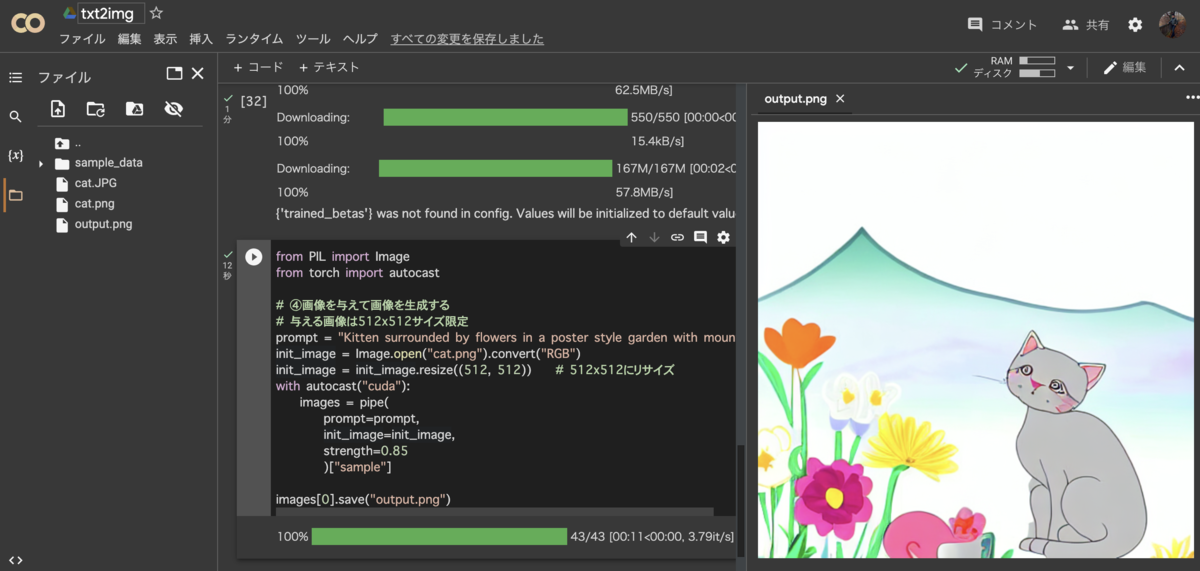
ここでは雑な手書きで、花が咲く庭にいる猫を描いてみた。注意点として画像は512x512ピクセルで作成すること。

これを絵の方向付けとして、img2imgでAI画像を生成する事例を示す。
導入ステップ④A:Google colabのGPU設定
- Google colabのURLにアクセス
2.ノートブックを新規作成する
3.メニューの「編集」ー「設定」をクリック
4.出てきた設定画面でハードウェアアクセラレータを「GPU」に変更
導入ステップ⑤A:img2imgのStable Diffusionの設定を書く
4つのPythonプログラムのみ記載する。txt2imgと同じ手順で出来る。
①Stable Diffusionパッケージをインストール
# ①Stable Diffusionパッケージをインストール # img2img対応したバージョンをインストールするためにGitHubのリポジトリを指定 !pip install transformers scipy ftfy !pip install git+https://github.com/huggingface/diffusers.git
②Hugging Faceへのアクセストークンをトークン変数に格納
# ②Hugging Faceへのアクセストークンをトークン変数に格納 MyTOKEN="<HugginFace HubのサイトでコピーしたAccess Tokenをここに入れる>"
③StableDiffusionパイプラインを準備する
import torch
from diffusers import StableDiffusionImg2ImgPipeline
# ③StableDiffusionパイプラインを準備する
pipe = StableDiffusionImg2ImgPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4",
revision="fp16",
torch_dtype=torch.float16,
use_auth_token=MyTOKEN
).to("cuda")
④プロンプトを与えて画像を生成する
※プロンプトは元画像を参照して生成する際に与えたい情報を記載する
※元画像のファイル名は大文字小文字の違いを認識するので注意
from PIL import Image
from torch import autocast
# ④画像を与えて画像を生成する
# 与える画像は512x512サイズ限定
prompt = "Kitten surrounded by flowers in a poster style garden with mountains in the distance"
init_image = Image.open("<アップロードしたファイル名をここに入れる>").convert("RGB")
init_image = init_image.resize((512, 512)) # 512x512にリサイズ
with autocast("cuda"):
images = pipe(
prompt=prompt,
init_image=init_image,
strength=0.85
)["sample"]
images[0].save("output.png")
導入ステップ⑥A:img2imgを実行
今回は元の画像を参照するので、512x512の画像をあらかじめアップロードしておく。アップロード方法は、Colabの左側にあるフォルダアイコンをクリックしてファイル一覧を表示してから、アップロードしたいファイルをColabのファイル一覧へドラッグ&ドロップすればよい(表示されない場合はファイルの一覧表示を更新)。
準備が整ったら、前記同様に4ブロックのPythonコードを順に実行して、生成されたoutput.pngが確認出来ればOK。
エラーの対策
- 設定の「GPU」指定を忘れていないか
- uploadするファイル名を間違えていないか
- 512x512の画像か
- アクセスキーの間違いや破損。簡単なのでアクセスキーの作り直しがお勧め
- どこかにエラーがあった際は、最初のコードから全て再実行させること
元の絵と見比べてみる

雑な絵が生まれ変わった。
【実例3】Waifu Diffusion,Trinart Diffusionで二次元画像を生成
実例1のコードに対して利用したモデルを指定するだけで、Stable Diffusion標準モデル以外のWaifuやTrinartなどのモデルが使える。プロンプトは「cute cat ear maid」に変更している。
ブロック③の変更箇所のみ記載(実例1のコードに対して1行の変更だけでOK)
# モデル:Stable Diffusion 1.4を使用する場合
pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4", # 変更箇所はこの行のみ
use_auth_token=MyTOKEN
).to("cuda")
# モデル:Waifu Diffusion を使用する場合
pipe = StableDiffusionPipeline.from_pretrained(
"hakurei/waifu-diffusion", # 変更箇所はこの行のみ
use_auth_token=MyTOKEN
).to("cuda")
# モデル:Trinart Diffusion V2 を使用する場合
pipe = StableDiffusionPipeline.from_pretrained(
"ayan4m1/trinart_diffusers_v2”", # 変更箇所はこの行のみ
use_auth_token=MyTOKEN
).to("cuda")
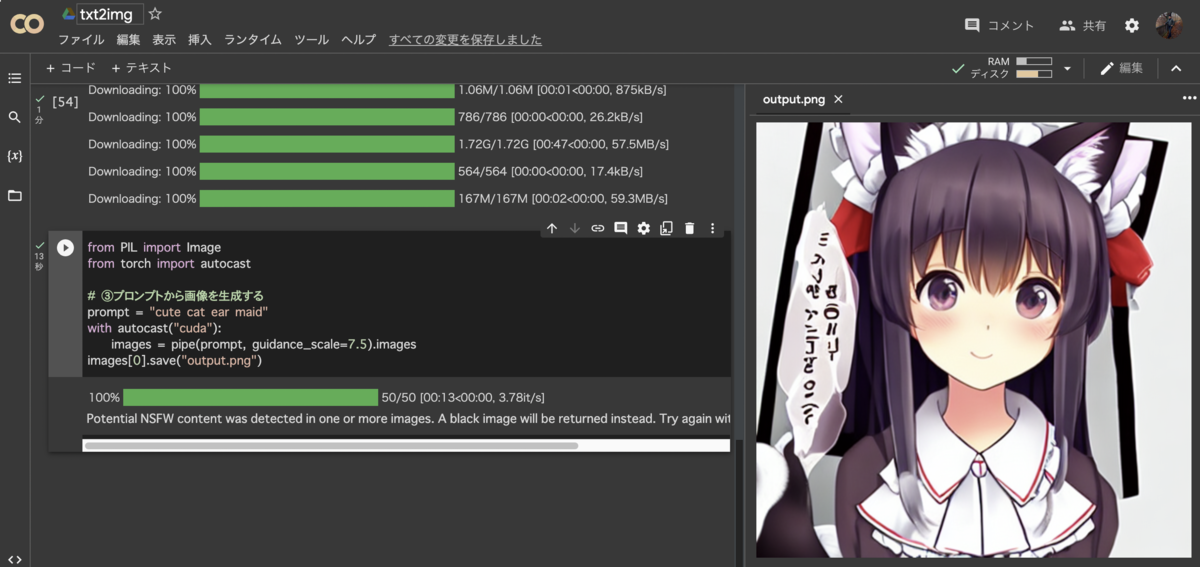
うーん、ヤバい。生成されるレベルが高く、ハズレが出ないw。

※その他多数あるモデルの紹介記事。いずれも同様に使える。
programmingforever.hatenablog.com
APIリファレンス
「StableDiffusionパイプライン」のpipeのパラメータ紹介
- prompt (str or List[str]) : プロンプト
- height (int, optional, defaults to 512) : 生成する画像の高さ
- width (int, optional, defaults to 512) : 生成する画像の幅
- num_inference_steps (int, optional, defaults to 50) : ノイズ除去のステップ数
- guidance_scale (float, optional, defaults to 7.5) : プロンプトに従う度合い (7〜11程度)
- eta (float, optional, defaults to 0.0) : eta (eta=0.0 は決定論的サンプリング)
- generator (torch.Generator, optional) : 乱数ジェネレータ
- latents (torch.FloatTensor, optional) : 事前に生成されたノイジーな潜在変数
- output_type (str, optional, defaults to "pil") : 出力種別
- return_dict (bool, optional, defaults to True) : tupleの代わりにStableDiffusionPipelineOutputを返すかどうか
- 戻り値 : tuple or StableDiffusionPipelineOutput
StableDiffusionPipelineOutputのプロパティ
- images (List[PIL.Image.Image] or np.ndarray) : 長さbatch_sizeのPIL画像のリスト または shape(batch_size,height,width,num_channels)のnumpy配列。
- nsfw_content_detected (List[bool]) : 生成画像がNSFW(not-safe-for-work)かどうかのリスト。
参考記事
今回の記事は、以下の先行開拓された方々の記事を参考に、未経験者向けにまとめた。