GoogleDrive上で実行
この記事は前にまとめたGoogleDrive上にAUTOMATIC1111のcloneを実装する運用に、比較実証などで高速にモデルを切り替える方法を加えたもの。AUTOMATIC1111はロードした5つ程のモデルを動的に切り替えて運用出来るが、モデルを高速にセットしたい、あるいはもっと多数のモデルを切り替えたいなどのニーズに応えるべくモデルを高速かつ簡単に入れ替える方法を説明する。ここまで来ると自分のPCで運用しているレベルの便利さを感じられるだろう。
この記事を実行する上での注意点
- おそらく有料のcolab proのハイメモリの設定にしないとメモリーオーバーで停止すると思われる
では順に従って実際に行ってみよう。
①colabの実行ノートを用意:
GoogleDrive上にAUTOMATIC1111のcloneを実装した上で、AUTOMATIC1111を実行するコードは以下のわずか5行だけで動作する(コメント行を除く)。
# ①GoogleDriveマウント
from google.colab import drive
drive.mount('/content/drive')
# ②GoogleDrive上のAUTOMATIC cloneに移動、更新の差分取込
%cd /content/drive/MyDrive/stable-diffusion-webui
!git pull https://github.com/AUTOMATIC1111/stable-diffusion-webui
# ③実行
!COMMANDLINE_ARGS="--share --gradio-debug --gradio-auth me:qwerty" REQS_FILE="requirements.txt" python launch.py
※GoogleDrive上にAUTOMATIC1111をクローンする方法は下の記事で説明している。
programmingforever.hatenablog.com
②GoogleDriveアプリをPCにインストール
GoogleDriveアプリをPCにインストールすると、Windows、MacでGoogleDriveのフォルダやファイルをあたかも自分のPCのフォルダの様に扱える。
ここでGoogleDriveアプリをインストールする理由は、素早くモデルを移動させるため。
今からの作業では、GoogleDriveに保存した多数のモデルの中から、利用したいものだけをGoogleDrive上のAUTOMATIC1111のcloneの中のモデルを格納するフォルダに入れる必要がある。しかしモデルはいずれも数GB以上あるためコピーの場合は相当に時間がかかってしまう。また大容量なので二重にモデルがあるのも勿体無い。
そこでGoogleDriveアプリを使って、一つの窓に表示したモデル格納フォルダから、もう一つの窓に表示したAUTOMATIC1111のcloneの中のモデルを格納するフォルダへ、モデルをドラッグ&ドロップするとコピーではなく移動になるので一瞬でモデルが移動する。
下記リンクで「パソコン版ドライブをダウンロード」を選ぶとインストールできる。なお、インストール方法は標準の「ストリーミング」を選ぶとPC側にメモリを食うモデルのファイルを置かなくて済むのでおすすめ。
www.google.com
③モデルをAUTOMATIC1111 cloneのモデル格納フォルダへ移動
- Windowsならエクスプローラー、MacならFinderで、それぞれ2つ窓を開く
- 一つ目の窓で左側で「Google Drive」を見つけて、MyDriveをクリックする
- 表示はリスト表示が扱いやすい
- 一つの窓に色々とモデルを格納しているフォルダを選択
- もう一つの窓にAUTOMATIC1111のcloneの中のモデルを格納するフォルダを選択
- →格納フォルダ:MyDrive/stable-diffusion-webui/models/Stable-diffusion/
- 必要なモデルをドラッグ&ドロップするとコピーではなく移動になるので一瞬でモデルが移動する
 ドラッグ&ドロップしている状態
ドラッグ&ドロップしている状態
例えばNovelAI,Anything3.0,EimisAnimeDiffusion,Elysium_Anime_V2,Evt_V3_ema、以上5つのモデルをMyDrive/stable-diffusion-webui/models/sSable-diffusion/に移動させてみる。
 NovelAI,Anything3.0,EimisAnimeDiffusion,Elysium_Anime_V2,Evt_V3_emaの5つのモデルを移動させた
NovelAI,Anything3.0,EimisAnimeDiffusion,Elysium_Anime_V2,Evt_V3_emaの5つのモデルを移動させた
④ノートを実行
前記①のノートを実行する。AUTOMATIC1111が起動したら一番左上の欄にある下矢印をクリックすると、5つのモデルが表示されていることがわかる。ここで好きなモデルを選べば、そのモデルを用いた生成が行える。
 ロードした5つのモデルが選択可能
ロードした5つのモデルが選択可能
⑤モデルを入れ替える
AUTOMATIC1111を起動したままで、5つのモデルを総入れ替えしてみる。
- 同様にWindowsならエクスプローラー、MacならFinderで、それぞれ2つ窓を開く
- 一つの窓に色々とモデルを格納しているフォルダを選択
- もう一つの窓にAUTOMATIC1111のcloneの中のモデルを格納するフォルダを選択
- →格納フォルダ:MyDrive/stable-diffusion-webui/models/sSable-diffusion/
- 現在選ばれている5つのモデルを元に戻す(空にする)
- 必要なモデルをドラッグ&ドロップする(コピーではなく一瞬でモデルが移動する)
今度は852話さんが作られた8528-Diffusion,derrida_final,HD-17,trinart_step6000,wd-v-1-3-float、の5つのモデルを選ぶ
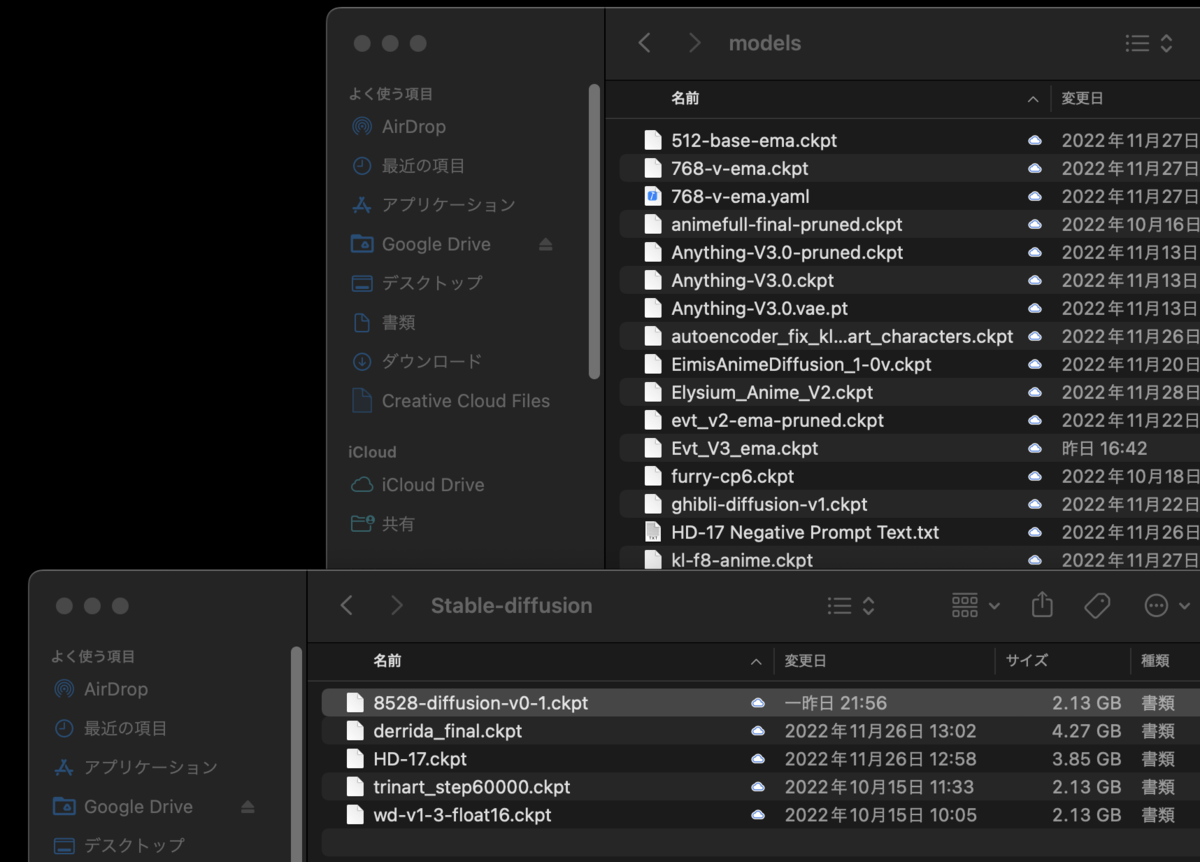 8528-Diffusion,derrida_final,HD-17,trinart_step6000,wd-v-1-3-floatの5つを選ぶ
8528-Diffusion,derrida_final,HD-17,trinart_step6000,wd-v-1-3-floatの5つを選ぶ
移動が終わったら、AUTOMATIC1111の一番左上の欄の下矢印の隣にあるリロードボタンを押すと、モデルが全て入れ替わっていることがわかる。
 モデルが入れ替わった
モデルが入れ替わった
この様に高速にモデルを入れ替えることで、多数のモデルの比較実証が容易に行える様になる。
VAEなども同様
モデル以外のVAEやTIも同様に配置出来る。配置方法などを記載した記事を紹介する。
programmingforever.hatenablog.com






