個人が学習させたモデルで画像生成出来る
日進月歩、秒進分歩という言葉がピッタリのAI画像生成だが、数日前に「Stable Diffusion Conceptualizer」のWebサイトが登場した。誰でも複数枚以上の画像データさえあれば、それを追加学習させたStable Diffusionで自由に画像生成出来る。これをTextual Inversionと称しているが、実際に世界中で作られたデータセットによる画像生成を以下のリンク先で試せる(現在で350以上登録済み)。
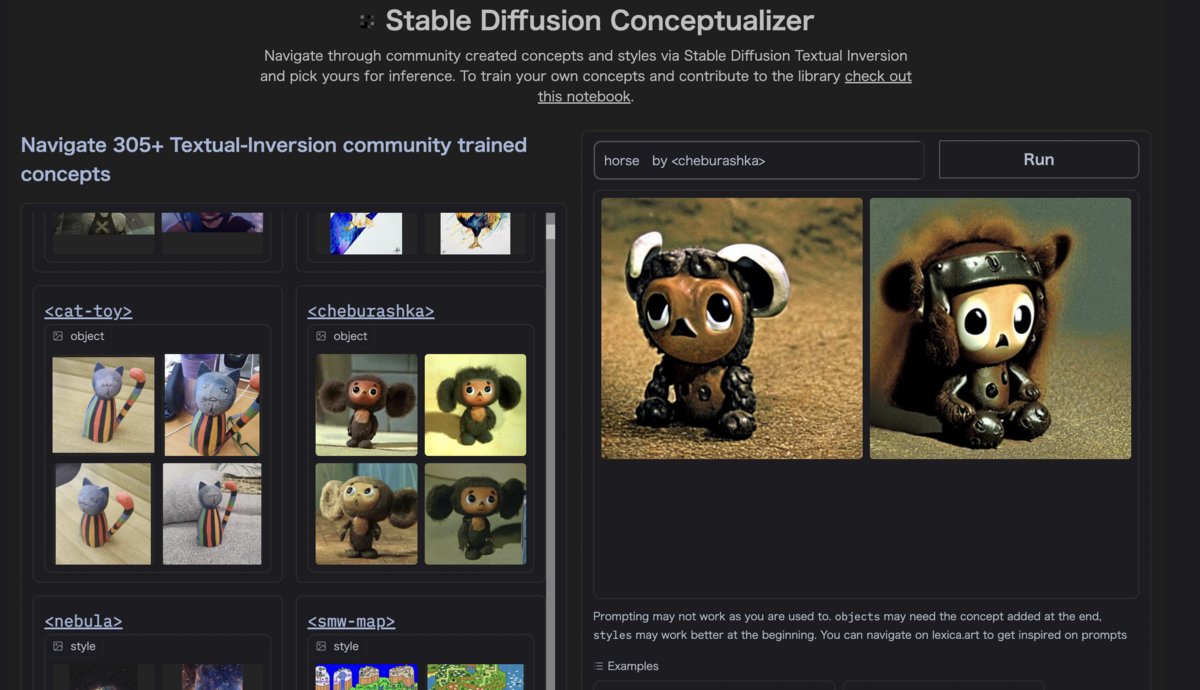
まず画面の左にあるコミュニティで作られた様々な画像データセットを選び、次に右のプロンプト内でその画像データセットを指定する。
一例としてチェブラーシカのデータセットを用いた「馬」を生成してみた。生成された図の右の方はたてがみもあって、それっぽい(?)。
プロンプトの記載例: horse by <cheburashka>
※記号の<>を付けて、左窓にある好みのデータセットを指定
現在負荷が重いため作成時にエラーになることが多いが、諦めずにクリックすると何回かに1回は実行できる
話題になったmimicと同じ
これは1日でサービス停止などで話題になった、イラストレータの画風の特徴を学ばせて画像生成させるmimicと同じTextual Inversion技術である。Textual InversionはStableDiffusionの標準機能であり、今後この流れは止められないだろう。