Gitのfile管理方法
Gitは内部のfile管理のイメージを掴むと理解が一気に進む。そこで図とログを同時に扱ってGitが3大ツリーでfileをどう扱っているかなどを説明しgit resetの動きも理解出来る図を掲載した。
Gitの3大ツリーでのfileの扱い
3大ツリーでのfileの扱いはそれぞれ下記の様に異なっている。
- 作業ディレクトリ(Working directory):編集作業を行うフォルダを指し、各fileはシェルやエディターで自由に扱える。fileはGitが追跡するfileとGitが追跡しない対象外のfileが混在する
- staging(ステージング、index、インデックス):次のcommit候補一式(Gitが追跡する全file)を、blob(object)と称する圧縮独自フォーマットに変換して保管している
- commit(コミット履歴):staging同様に各commit毎に、GItが追跡する全fileをblobで保管している。但し以前のcommitと変化が無いfileは参照Linkを用いることで同一fileの重複保存を回避している
blobはfileにヘッダーを追加してからSHA1でハッシュ化を行い、それらの情報を付与したfileをzlibで圧縮した上で保存する。SHA1は objectのIDとして利用出来るので、何らかのミスでfileを失ってもそのSHA1を手がかりに復活させる方法が存在する。
サンプル
理解のためにシンプルな構成を想定する(下図)。
- 全部で4commit
- 各commit毎にa.sh、b.sh、c.sh、d.shとfileを1つずつ追加する
- 3番目のcommit前にa.shの内容を修正してからcommitする
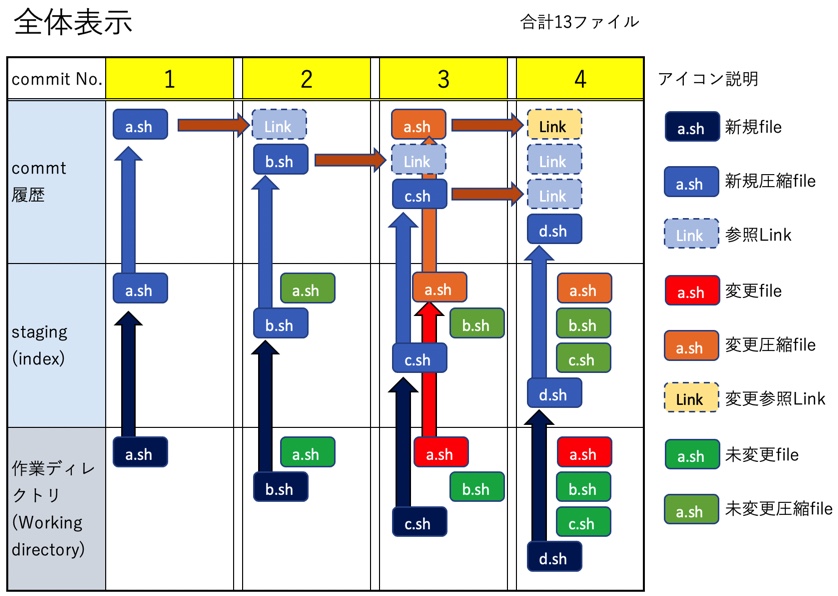
これを用いて1つずつcommitを進めてみる。
1回目のcommitまで
a.shを追加し、staging&commitを行う。fileは作業ディレクトリに1個、stagingにblobに変化して1個、commitにもblobが1個、以上3個のfileが存在する。
注意:fileの扱いに特化して説明する関係上、treeおよびcommit objectは除外する
$ touch a.sh $ git add . $ git commit -m "最初のcommit"
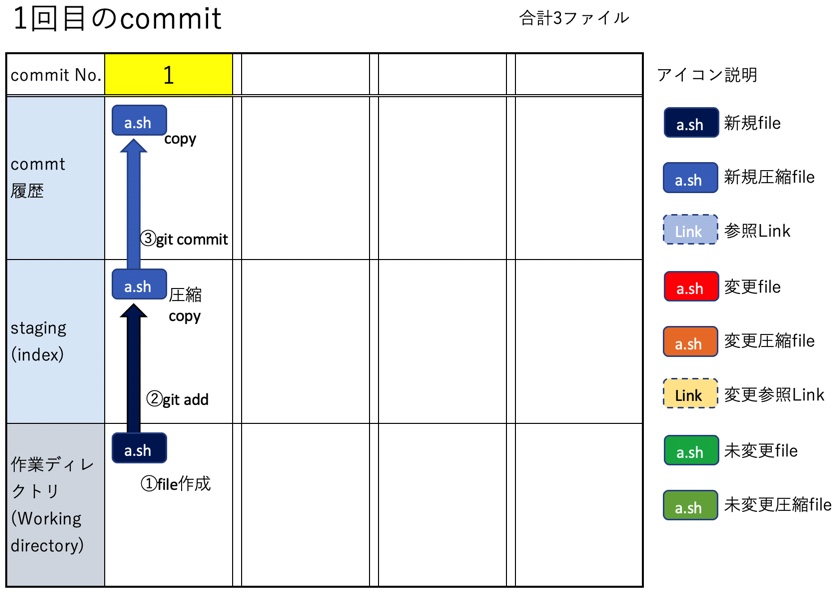
stagingの確認:git ls-filesコマンドでstagingされているfile(blob)一覧が出る(--stageオプションを加えると各fileのID(SHA1)も確認出来る)。以下ではa.shがstagingされているのが見える。
$ git ls-files --stage 100644 579da06934bd26a1a2f791021a989b95dfcd8a39 0 a.sh
commitの確認:git logでcommitのID(SHA1)を確認後にgit show ID(SHA1) --name-onlyと打つと、そのcommitで保存されたfile(blob)一覧が出る。以下ではcommitにa.shが入っている事が分かる。
$ git log --oneline ef11425 (HEAD -> master) 最初のcommit $ git show ef11 --name-only commit ef11425c7169155b5c167dcfc3837c250613d12f Author: Date: Sun Sep 19 15:33:23 2021 +0900 最初のcommit a.sh
2回目のcommitまで
b.shを追加し、staging&commitを行う。fileは作業ディレクトリに2個、stagingにblobに変化して2個、commitにもblobが2個、以上6個のfileが存在する。なお各commitにはGitの追跡fileが全て登録されるが、下図のa.shの様に前回のcommitから変更されていない同一内容のfileはそのfileを指し示すLinkを作成することで同一fileの重複保存を避けている。
$ touch b.sh $ git add . $ git commit -m "2回目のcommit"
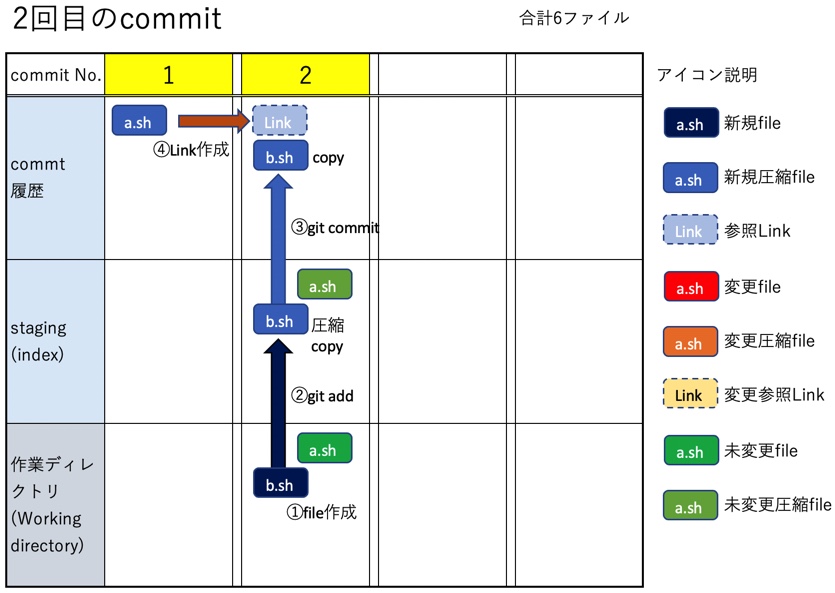
同様にstagingにはa.shとb.sh、commitには新規追加したb.shだけが入っているのが分かる。
$ git ls-files --stage 100644 579da06934bd26a1a2f791021a989b95dfcd8a39 0 a.sh 100644 5d308e1d060b0c387d452cf4747f89ecb9935851 0 b.sh $ git log --oneline 1999418 (HEAD -> master) 2番目のcommit ef11425 最初のcommit $ git show 1999 --name-only commit 1999418d81ddda2f848a3e91cdd65d7c211963a0 Author: Date: Sun Sep 19 15:46:49 2021 +0900 2番目のcommit b.sh
3回目のcommitまで
c.shを追加し、さらにa.shの内容を修正した上でstaging&commitを行う。fileは作業ディレクトリに3個、stagingにblobに変化して3個、そしてcommitにはblobが4個登録される(合計10個のfile)。これはGitがfileの差分管理ではなく、変更がある毎に別のfileとして保存するためで、図の様にa.shの変更前のblobがNo.1commit、a.shの変更後のblobがNo.3commitにそれぞれ保管されている。差分管理ではなく別fileとして管理する方式を取ったことで、branchやreset、rebaseなどの処理が容易に行える様になっている。
$ touch c.sh # - c.shを追加 $ vi a.sh # - a.shを編集 $ git add . $ git commit -m "3回目のcommit"
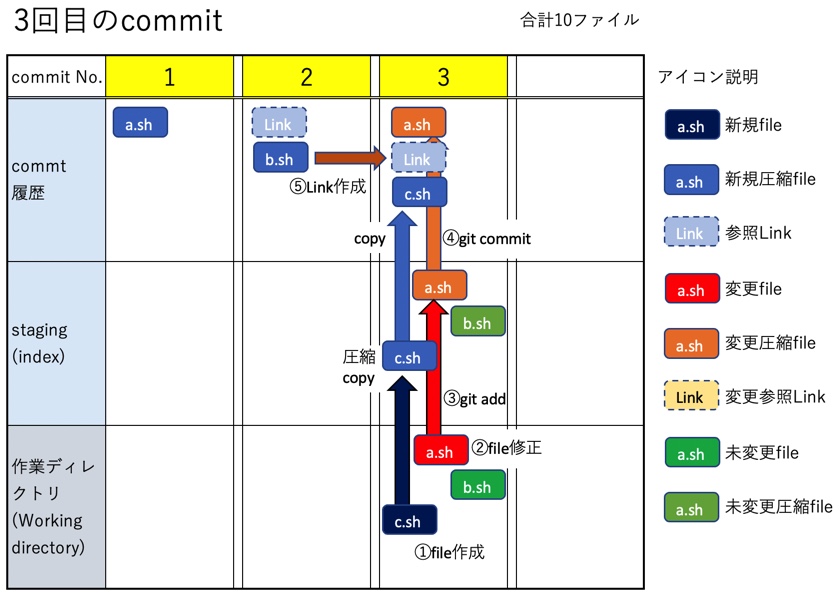
a.shを変更、c.shを追加したのでstagingには3file(blob)が入る。なおa.shは内容が変更されたためSHA1ハッシュが違うIDに変更されている。
commitは変更されたa.shと新規のc.shの2つのfile(blob)が保存されている。
$ git ls-files --stage 100644 d7754295c833a6a8147c6bd22122d145d2f09b47 0 a.sh 100644 5d308e1d060b0c387d452cf4747f89ecb9935851 0 b.sh 100644 61780798228d17af2d34fce4cfbdf35556832472 0 c.sh $ git log --oneline 8a20ac3 (HEAD -> master) 3番目のcommit 1999418 2番目のcommit ef11425 最初のcommit $ git show 8a20 --name-only commit 8a20ac30c95d90fc1c92aaa7b433e91ffe7f8d8f Author: Date: Sun Sep 19 15:50:03 2021 +0900 3番目のcommit a.sh c.sh
4回目のcommitまで
d.shを追加してstaging&commitを行う。fileは作業ディレクトリに4個、stagingにblobが4個、commitにはblobが5個登録される(合計13個のfile)。
$ touch d.sh # - d.shを追加 $ git add . $ git commit -m "4回目のcommit"
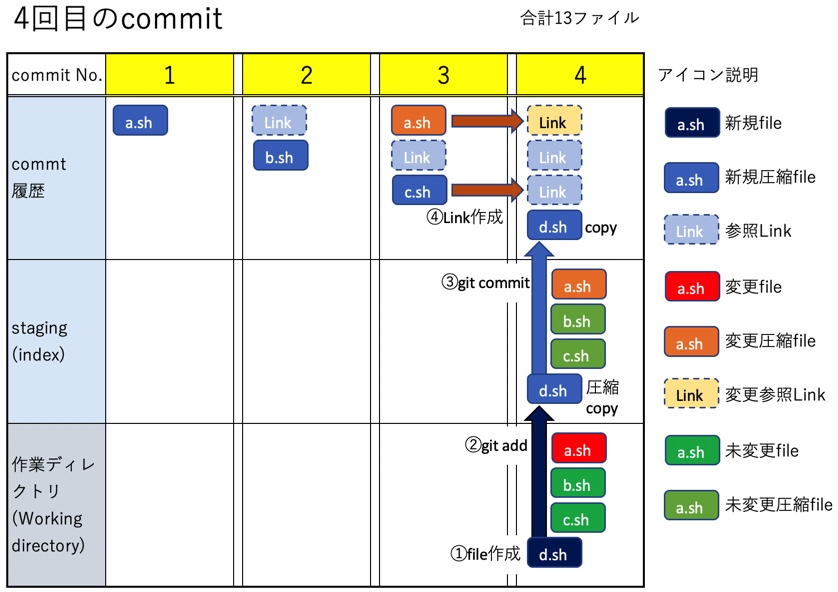
以上4commitの結果、stagingには4file(blob)が入っている。またcommitは最終追加のd.shが保存されている。
$ git ls-files --stage 100644 d7754295c833a6a8147c6bd22122d145d2f09b47 0 a.sh 100644 5d308e1d060b0c387d452cf4747f89ecb9935851 0 b.sh 100644 61780798228d17af2d34fce4cfbdf35556832472 0 c.sh 100644 f2ad6c76f0115a6ba5b00456a849810e7ec0af20 0 d.sh $ git log --oneline cac41d4 (HEAD -> master) 4番目のcommit 8a20ac3 3番目のcommit 1999418 2番目のcommit ef11425 最初のcommit $ git show cac4 --name-only commit cac41d483660425387f0488f0551df45f9c9e186 (HEAD -> master) Author: Date: Sun Sep 19 15:51:13 2021 +0900 4番目のcommit d.sh
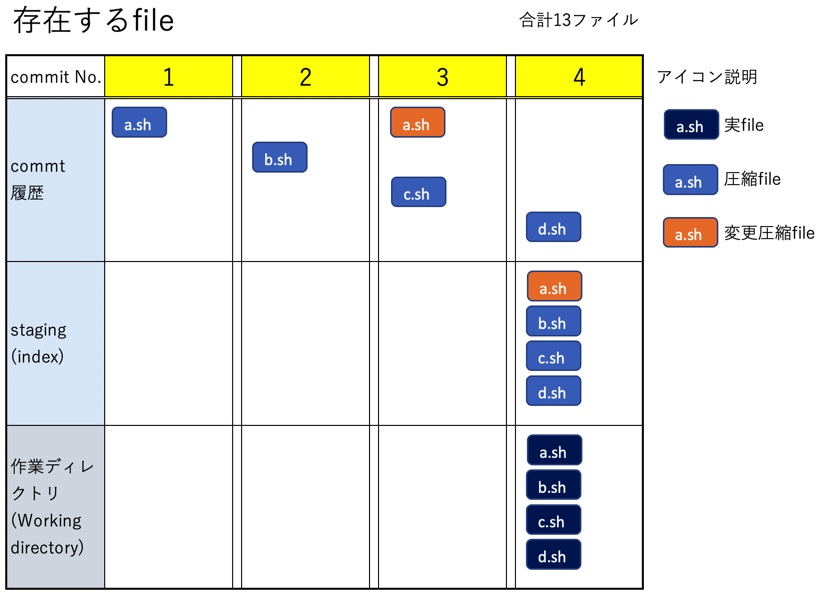
fileの総数
ここで改めてfileの総数を数えると、作業ディレクトリに4個、stagingに4個(blob)、commit履歴に5個(blob)の合計13個になった。前記した通りa.shはcommit履歴のNo.1 commitに初期版、No.3 commitに修正版と内容が異なるfileが2つ存在している。
高効率なfile保存
開発では各commit毎に1つのfileを修正&commitするパターンが多く、仮に10個のfileで30commitある場合は、作業ディレクトリに10個、stagingに10個(blob)、commitに30個(blob)の合計50fileが存在する事になる。
仮に10fileの各大きさを10kバイトとした場合、10k*10=100kバイトの実容量に対して、blobの圧縮率を1/4とするとstagingとcommit履歴を足しても2.5k*(10+30)=100kバイト程度に収まり、スマートにcommit履歴を保存出来ている計算となる。
実はGitは一定期間が過ぎるとgit gcコマンドが自動で走って、file(blob)の各差分をバイナリfileにまとめる方法でより高圧縮に保存する。詳しくは下記の記事を参照して欲しい。
programmingforever.hatenablog.com
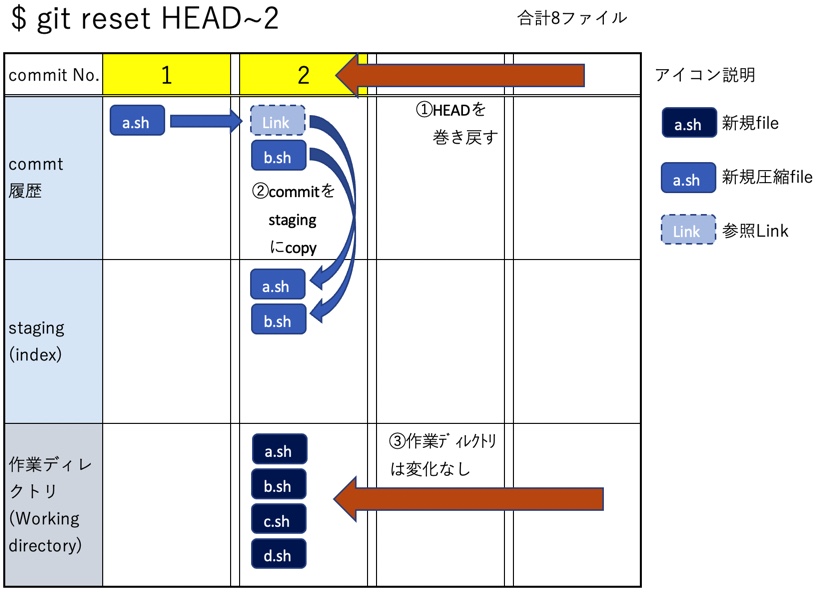
git resetを実行する
ここで2つ前のcommitまでresetすべくgit reset HEAD~2を実行してみる
$ git reset HEAD~2
HEADが移動して、No.2のcommit履歴からblobをstagingに戻す(copy)。a.shはLink先を辿ってNo.1のcommit履歴からblobを取り出す。resetは--mixedの動作なので作業ディレクトリは最新commitの状態のままだ。
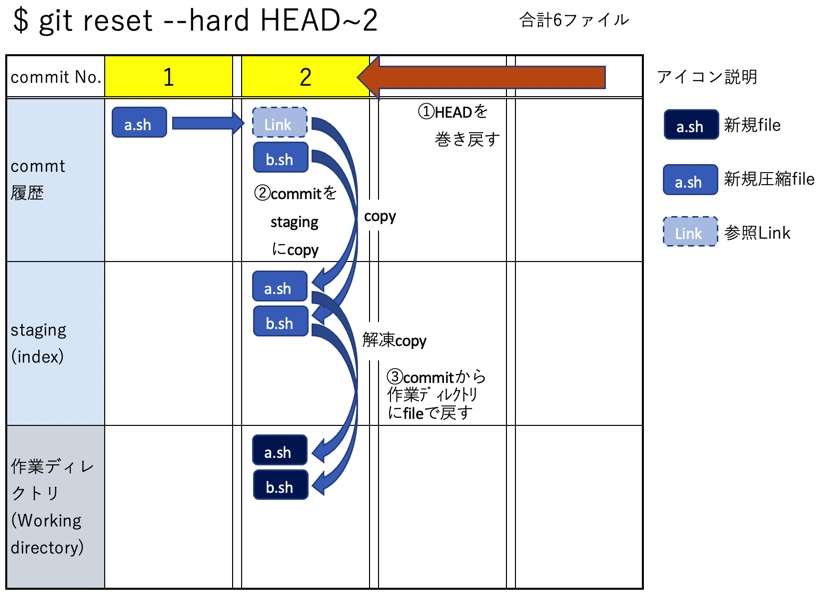
git reset --hardを実行すると
上記を元に戻してから、今度は2つ前のcommitまでをreset --hardで実行してみる
$ git reset ORIG_HEAD # - 元に戻す $ git reset --hard HEAD~2
HEADが移動して、No.2のcommit履歴からblobをstagingに戻す(copy)。a.shはLink先を辿ってNo.1のcommit履歴からblobを取り出す。次にresetは--hardの動作なのでstagingに戻したblobを通常のfileに解凍した上で作業ディレクトリに展開する(作業ディレクトリは更新されるので、元の状態は破壊される点に注意)。
いずれもGitが差分管理ではなく、変更file管理方式を採用していることでresetなどのcommit編集が容易に行えることが分かる。