述べたいこと
Gitのステージング(Staging, index)を正しく理解して活用するとcommit履歴が整理できる

誰を対象にした記事か
この記事は、以下の様にstagingを考えるgit初心者向けの技術解説記事。
- なぜstaging(ステージング, index, インデックス)があるのか今ひとつ分からない
- いちいちcommit前にgit add .するのが面倒
- commitしたら常に -amオプションが有効になってstagingとcommitが一気に出来ればいいのに
そんな方がGitのstagingに関する2つの情報を知ると、今後の活用方法が変わるかもしれない。
- 情報:stagingというバッファを活用する
- 情報:ファイルの一部の行だけを分割staging&commit出来る
この記事を理解するために必要な情報
- Gitに対して基本理解があり、少しでも使ったことがある方
- Gitには①作業ディレクトリ(Working directory)、②ステージング(Staging, index)、③コミット履歴の三大ツリーがあることが分かる方
現状の何が問題か
stagingの役割が今ひとつ分からない。そんな人のcommit履歴を見ると大抵こうなっているだろう(一番上が最新commit)
$ git log --oneline d31d388 (HEAD -> master) Ver.2.2リファクタリング完了 ---(動作OK) ee0d7dc リファクタリング、しかしバグが出て修正中 ---(動作NG) 9a6635e デバッグコード削除完了OK ---(動作OK) 731c3b8 バグfix ---(動作OK) 26e6cbb 通信バグ修正中 ---(動作NG) 6255bc8 表示バグ修正中 ---(動作NG) 2b4814e コンパイルエラーfix ---(動作NG) b96710c さらにコードを追加実装 ---(動作NG) 9718ee6 コードを追加実装 ---(動作NG) e13db9b Ver.2.2変更仕様の実装一段落 ---(動作NG) f706e98 Ver2.1リファクタリング完了 ---(前Ver.の最終コミット)
変更実装に着手してからコードを重ねる毎にcommit、コンパイラエラー解消でcommit、バグ修正で自分なりのポイントでcommit、バグfixでcommit、デバッグコード削除、リファクタリングなどでそれぞれcommitと、合計10個のcommitがある。開発者にとっては作業ファイルを失わない様に保管する目的でcommitしている。
しかしながら本来のcommitは第三者とも共有するため下記の様なポリシーで行われる。
- 動作すること(レビューに於ける動作確認のため)
- レビュー対象にならないムダなcommitを避けること
- ファイルや関数を追加・削除・リネーム時
- 機能追加や仕様変更時
- リファクタリング完了時(リファクタリングと機能追加・変更は分ける)
- 後でここに戻りたいと思う所・きりのいい所
- 作業から長期間離れるとき
これらの観点から上記のcommitを見ると、必要なcommitはこの二つだけ。
$ git log --oneline d31d388 (HEAD -> master) Ver.2.2リファクタリング完了 ---(動作OK) 9a6635e デバッグコード削除完了OK ---(動作OK) f706e98 Ver2.1リファクタリング完了 ---(前Ver.の最終コミット)
以下、最初に「改善1」でムダなcommitを減らす方法を伝える。次に「改善2」でファイルの一部の行だけをcommitする方法を記載する。
commit整理は
git rebaseやgit resetを用いたcommit履歴編集が一般的だが、ここではcommit履歴編集自体を不要にするstaging活用法を紹介する(比較的軽微な修正向きの方法)
改善1:stagingのフル活用=ムダなcommitを抑制する
今までは編集作業が完了したら儀式のようにgit add .を打ち、即commitしていると思う。これではstagingは余分なひと手間にしか過ぎないと感じるのも無理はない。git本来の3大ツリー機能を使わず、作業ディレクトリとcommit履歴の2つのツリーだけを使うやり方に陥った状態と言える。
まずstagingを活用していない模範的な例を図にしてみよう。
簡略化のために編集を行う対象ファイルは、hoge.shのみとする(作業ディレクトリ内に管理対象外ファイルも無いものとする)。 編集されるコードは「 # Rev.A」のコメントだけとする。編集を重ねてRev.b, c, d...と進むものとする。 一つ前のcommitでコードが「# Rev.B」に変わっているものとする。 最新commitの「# Rev.C」を今から編集する。
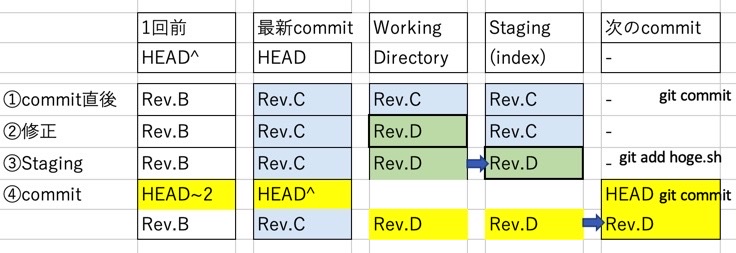
図の番号順に説明すると、
- 前のcommit直後。作業ディレクトリもstagingも同一内容
- 作業ディレクトリ内の hoge.sh を編集して「Rev.D」になった
- staging:git add . コマンドで作業ディレクトリの変更をstagingする
- commit:git commit コマンドでcommit。再び作業ディレクトリ、staging、commitの内容が一致する
今までは上記の3と4をほぼ同時に行なう形で、コードを追加して一段落したらcommit、エラーを解決したらcommit、バグに詰まってcommit、一部直してまたcommit、、、と作業内容の維持を目的としたcommitを繰り返していると思う。これが個人で開発するプロジェクトならまだ良いが、第三者がこんなcommitの履歴を見てもレビューが困難だ。そして半年後の自分もほぼ第三者と考えるべきで、せっかく個々目的に応じて開発を重ねてきたものがカオスなままというのは実にもったいない状態と言える。
そこでstagingの活用である。
実は変更の維持にcommitではなくstagingがバッファとして利用出来る。簡単に説明すると、編集完了後にgit add . コマンドでstagingしてもすぐにcommitをせず、引き続き編集作業が行える(ここが重要ポイント)。その結果、下記リストの様にgitの3大ツリーである作業ディレクトリ、staging、最新commit全ての内容が異なる状態になる。
- 最新commit:HEAD:作業前の最終保管(リポジトリ)ファイル(Rev.C)
- staging:ステージング前の変更を保持したファイル(Rev.D)
- 作業ディレクトリ:staging後に再びファイルを修正(Rev.E)
今までstagingはcommit前の何か儀式的なものと考えていた方は、作業ディレクトリとcommit履歴の二つだけ意識して、staging活用や3大ツリーが全て異なる状態をイメージ出来ていなかったと思う。
と言っても初めての方には「ちょっと何を言っているのか分からない」かもしれない。そこで下図を番号に従って順に解説する。
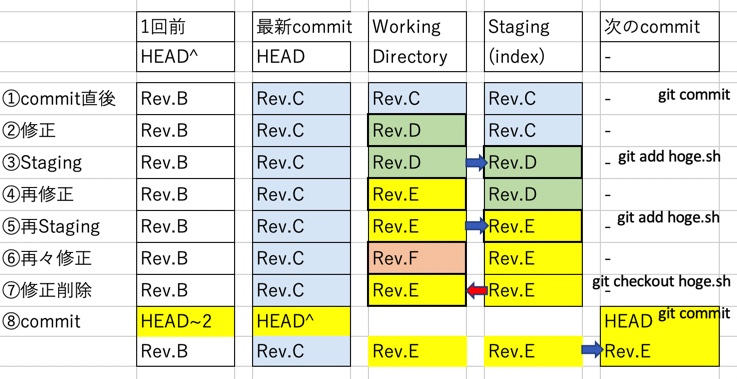
- 前のcommit直後。3大ツリーは全て同じ内容
- 編集作業:作業ディレクトリ内の hoge.sh を編集して「Rev.D」に変わった
- staging:git add hoge.sh コマンドで作業ディレクトリの変更をstagingする。作業ディレクトリとstagingは同じになる
- 編集作業:再びhoge.shを編集して「Rev.E」に変わった。3大ツリーの内容は全て異なる
- staging:再びgit add hoge.shコマンドでstagingする
- 編集作業:さらにhoge.shを編集して「Rev.F」に変わった。
- 編集破棄:上記6の編集が不要と判断し、git checkout hoge.shコマンドでstagingのデータを作業ディレクトリに戻す
- コミット:git commit コマンドでcommit。3大ツリーが再び全て同じ内容になる
まず上記の4に着目して欲しい。作業内容をstagingにひとまず保存して(commitをせず)、引き続き作業ディレクトリにファイル追加や編集作業を続行している。これにより、staging後の追加作業に対してデバッグ出来る。
次に上記の7も重要だ。stagingした後の編集作業にミスがあり破棄したいことは多々ある。その際にstagingに保管しておいた情報を作業ディレクトリに戻すことが出来るのだ。コマンドは「git checkout files」。
上記の注意点として、「git checkout HEAD files」の様にcommitを指定しないこと。その場合はcheckoutコマンドの動きが異なり、リポジトリから指定されたcommitの内容がロードされて作業ディレクトリとstagingの内容が消えてしまう(git stashなどによる保持が必要)。なおcheckoutの使い方は混乱しやすくresetとまとめて別記事で整理しているので確認して欲しい。
programmingforever.hatenablog.com
これを駆使すれば最初に記載した、とにかくcommit、commitの様な履歴commitが以下の様に変わる(2つしか追加されない)。
$ git log --oneline d31d388 (HEAD -> master) Ver.2.2リファクタリング完了 ---(動作OK) -------- リファクタリング、しかしバグが出て修正中 ---(commitせず、Stagingのみ) 9a6635e デバッグコード削除完了OK ---(動作OK) -------- バグfix ---(commitせず、Stagingのみ) -------- 通信バグ修正中 ---(commitせず、Stagingのみ) -------- 表示バグ修正中 ---(commitせず、Stagingのみ) -------- コンパイルエラーfix ---(commitせず、Stagingのみ) -------- さらにコードを追加実装 ---(commitせず、Stagingのみ) -------- コードを追加実装 ---(commitせず、Stagingのみ) -------- Ver.2.2変更仕様の実装一段落 ---(commitせず、Stagingのみ) f706e98 Ver2.1リファクタリング完了 ---(前Ver.の最終コミット)
今まで存在理由がよく分からなかったstagingを理解することで、作業の切れ目で無条件にcommitしてきた従来のやり方を変えられるのがわかるだろうか。まずこれで(特に第三者から見て)不要なcommitが削除出来る様になる。しかしこれだけではまだ不十分で、次のステップとして第三者がレビューしやすい様に、複数の変更要素を要素毎にcommitする必要がある。
改善2:ファイルの中の必要な行だけを個別staging&commitする
さて改善1で無駄なcommitを排除出来る様になったが、そうやって整理したcommitの中に仕様追加、ファイル追加、バグ修正、リファクタリングなどの複数の変更要素が含まれて、レビューワーから見るとカオスになっている場合は、複数のcommitに分割して整理すべきである。
あるいは変更要素が一つだけの場合も、不要なメモやデバッグコードの削除を効率よく行うことで1回のcommitで済ませたい。
そこで改善2として、改善1でstaging&commitする際に、ファイルの中の必要な行だけをstagingに上げる方法を紹介する。この方法をマスターすれば、整理された個別staging&個別commitが行える。
これは
git rebaseやgit resetを用いるcommit履歴編集でも同様に使える方法。詳細は後述の「意見」で述べる
「??変更したファイル単位ではなく、その変更した行の一部だけをcommitするってどういう意味??」
確かに初めての方にはこれも理解しにくい考えだと思う。しかしこう考えてみてほしい。作業ディレクトリの中にどれだけ多くのファイルやそれに含まれる多数の行があったとしてもgitから見た場合は行の集合体に過ぎず、全ての行を行単位で常に管理し続けていると。
gitでは編集で変更された1ないし複数行の単位を「1ハンク」と呼び、「作業ディレクトリの中で変更された行(ハンク)」をそれぞれ独立して管理するので、ある一つのファイルの中で定数変更した3行、アルゴリズム変更した5行、バグfixした1行をそれぞれ別要素の3つのハンクとして扱う。
それでは、gitがハンク単位で管理することを理解した上で、改善1で整理されたログファイルのバグfix完了とデバッグコード削除に関連するstagingとcommitにもう一度着目してみよう。
$ git log --oneline
---
9a6635e デバッグコード削除完了OK ---(動作OK)
-------- バグfix ---(commitせず、Stagingのみ)
---
このバグfixした際のステージングとcommitの作業を以下の様に工夫する(なおこの修正には3つの異なる変更要素が含まれていたとする)。
$ vi hoge.sh # (1) $ git stash # (2) $ git stash apply $ git reset HEAD --mixed # (3) stagingを一旦クリア $ git add -p . # (4) commitしたいハンクだけをstagingに加える $ git commit # (5) 必要なハンクのみcommit $ # --------------- # (6) $ git clean -df # (7) 不要ファイルを削除
- バグfixを完了させる(作業ディレクトリに動作可能な最新ファイル一式が入っている)
- git stash&git stash applyコマンド連打でミスした際にいつでもgit stash applyで上記1を復活出来る様にしておく
- git resetコマンドでstagingを直前commitの内容に戻す(次の作業で全ての変更箇所が見える様にする準備)。このresetはオプション無しのmixedで実行すること。間違っても--hardにはしないこと(全て消えてしまう)
- git add -pコマンドを実行する。すると複数箇所変更された行(ハンク)毎に対話モードで「それをstagingするか?」と聞かれるので、commit対象の変更に該当するハンクだけを選択あるいは編集してstagingし、それ以外はstagingしない
- commitしてその対象をコミットメッセージに書く(例:変更1::通信用定数を変更)
- 複数の変更要素が有れば必要なだけこの4-5を繰り返す
- stagingされていない残りのコードが不要なメモ類やデバッグコードだけになったら
git clean -dfで作業ディレクトリの不要ファイル/ フォルダを抹消する
結果として以下の様に3つの要素毎に整理されたcommit履歴が実現する。レビューも容易だ。
$ git log --oneline d31d388 (HEAD -> master) Ver.2.2リファクタリング完了 ---(動作OK) e82e6bd 変更3::入力待ちの時定数を10倍の200mSECに変更 2537ea1 変更2::温度算出を摂氏に変更 47292a5 変更1::通信用定数を変更 f706e98 Ver2.1リファクタリング完了 ---(前Ver.の最終コミット)
ぜひstagingを活用して欲しい。
なおcommitの分割作業で、staging/commtしたいハンクの量が膨大で相当な選択作業になってしまう場合もある。そんな時は逆にハンクをstagingから減らすgit reset -p コマンドを使ってstagingしたくないハンクを外してcommitするのが便利だ。次の分割commitでも同様の作業を行いたい場合は git add . で全てstagingしてから再度同じ作業を行う。逆にハンクを追加する方がよければ従前の git add -p コマンドを使う。
$ vi hoge.sh # (1) $ git stash # (2) $ git stash apply $ git reset -p # stagingされた中から不要なハンクを外す $ git commit # 必要なハンクのみcommit $ # --------------- # (6) $ git clean -df. # (7) 不要ファイルを削除
各コマンドでハンクを扱う方法を別記事にまとめている。行単位での編集も可能だ。
programmingforever.hatenablog.com
この作業で新しく作られる各commit毎に、git cleanコマンドを実行してcommitされたVersionで動作確認するのが望ましい。さもないと動作しない迷惑なcommitになる恐れがある。しかしstagingの段階で動作確認する方法はやや難度が高いため割愛する。
意見:commit後のrebaseやresetで十分では?
これはコーダーによって意見が異なるだろう。わずかな作業量でも都度commitする方もいるだろう。作業が個人のPCで閉じており共有される前であれば、重ねたcommitはいつでもrebaseやresetで整理出来る。
簡単にreset使用例を說明する。上記同様に作業着手から10程度のcommitを立てながら仕様変更対応が完了して動作するプログラムが作業ディレクトリにあり、commitが整理されていない状態としよう。その散らかったcommit前の、今回の作業開始点まで戻し(reset --mixed)、実装してきた変更要素毎に分割staging & commitをする。stagingの中身は戻した過去のcommitの内容に戻っているので、git add -pコマンドを使えば、最新の作業ディレクトリ内にある変更された全てのハンク(行の塊)が表示される。後は各ハンク毎に対話方式でステージングする/しないを選択する作業を行う。
つまり、commitを重ねた状態でも、改善①で説明したstagingで更新を重ねた状態でも、resetでハンク毎の分割staging & commitで整理する作業は同じになる。コマンドで比較してみる。
$ # -----commitせず更新ファイルがある場合 $ git reset HEAD --mixed # stagingを最新commit(HEAD)に戻す $ git add -p . # ハンク毎のstaging $ git commit # staging分をcommit $ # -----必要なだけ git add -p . とgit commitを繰り返す $ $ # ------commitを重ねた場合(SHA1 を指定commitとする) $ git reset SHA1 --mixed # stagingを指定commitに戻す $ git add -p . # ハンク毎のstaging $ git commit # staging分をcommit $ # -----必要なだけ git add -p . とgit commitを繰り返す
上記の通り、resetコマンドのcommit指定がHEAD(最新)か過去のcommitかという差だけだ。一仕事終えた後にrebaseやresetを使うのは適切な利用法だと言える。
意見:大規模変更でもなるべくcommitを避けるのか?
数日以上に渡る様な大規模な変更実装の場合も可能なら変更要素毎に切り分けて実装〜staging〜commitの繰り返しが良い。ただ個人が決めたタイミングで自由にcommitしても問題はないだろう。
この記事ではわずかな作業量かつ複数の変更要素を含む様な編集作業に伴うgit活用を想定しており、git add -pコマンドを用いるハンク毎のステージング作業が多過ぎて大変になる様なら逆に問題で、開発粒度を小さくすることを先に検討するべきだろう。
なお変更要素が一つのみの場合は当然ながら改善2の作業は不要で、シンプルに変更要素を編集してstaging、commitで完了する。理想的だが複数の変更要素が絡みあうのが通常であり、開発が一段落した後に変更要素を個別に整理するのは頭のモードも切り替えられて中々有益だと思う。