複数ブランチを同時編集
Gitで複数のブランチを同時編集したい場合、git checkout ブランチ名で頻繁に移動しながら編集することになるが、都度別ブランチのfileを確認しようとすると不便なため、全く別のフォルダに暫定的にコピーしたり、stashしたり、別クローンしたりなど結構手間がかかる作業を強いられがちになる。
その様な課題に対してGitは、1つのリポジトリに対して複数ブランチの各作業ディレクトリ(worktree)を同時展開して、編集作業やcommitをそれぞれの作業ディレクトリで並行して行える機能を提供している。コマンド名もgit worktree。

同時展開は、現在のブランチを展開する作業ディレクトリの下に、他のブランチがそれぞれサブディレクトリとなって存在する形で展開される(全く別のフォルダでも良い)。なのでディレクトリを移動するだけで各ブランチに入り、そのブランチに対するGit操作が行える。このサブディレクトリとして存在する各作業ディレクトリは仮想的な存在なので各ブランチ本体への操作とイコールであり、作業完了後このサブディレクトリは不要になるので抹消する。
VSCodeなどのエディターを用いれば各ブランチに該当するサブディレクトリを一覧して同時編集や差分表示が出来る。Git操作もVSCodeのターミナル画面のシェルでディレクトリを変更するだけで各ブランチに入ってそのブランチのcommitが行える。とても便利なので実例を示しながら紹介したい。
git worktreeコマンドを用いた同時編集の例
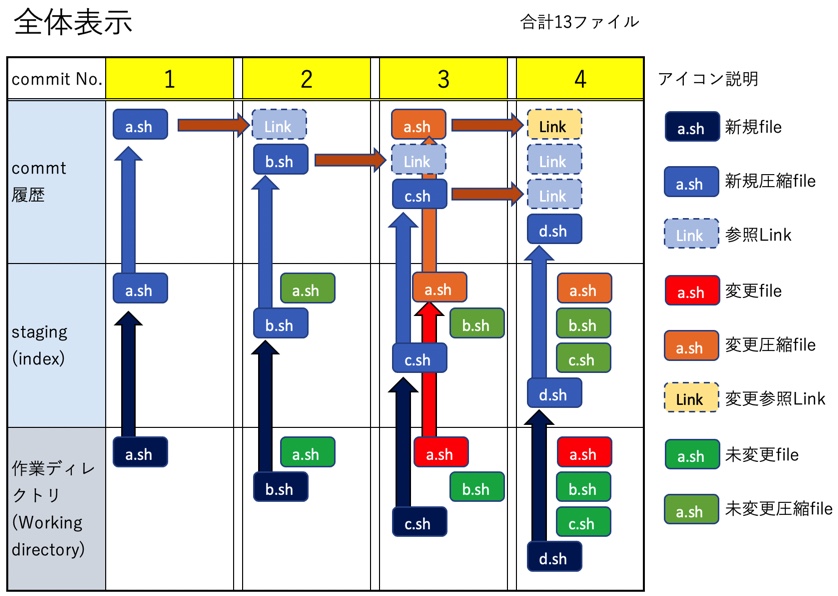
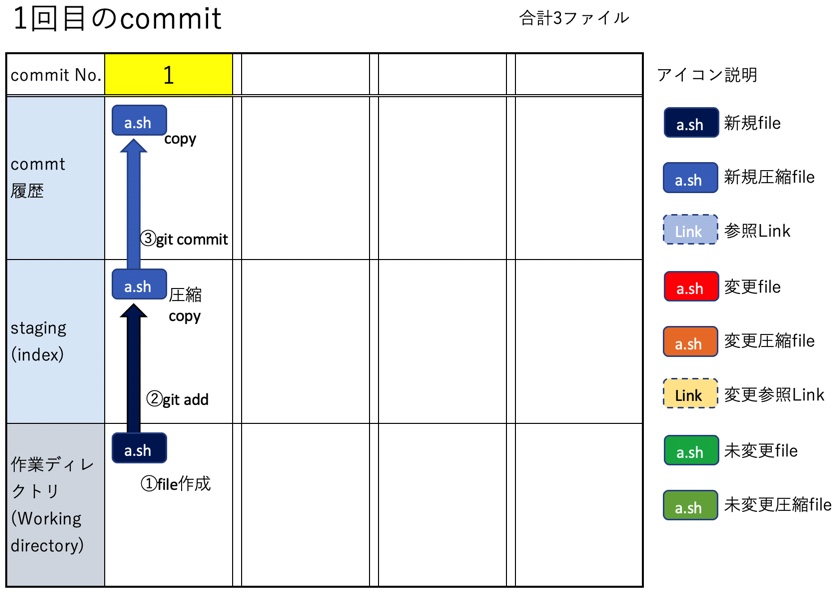
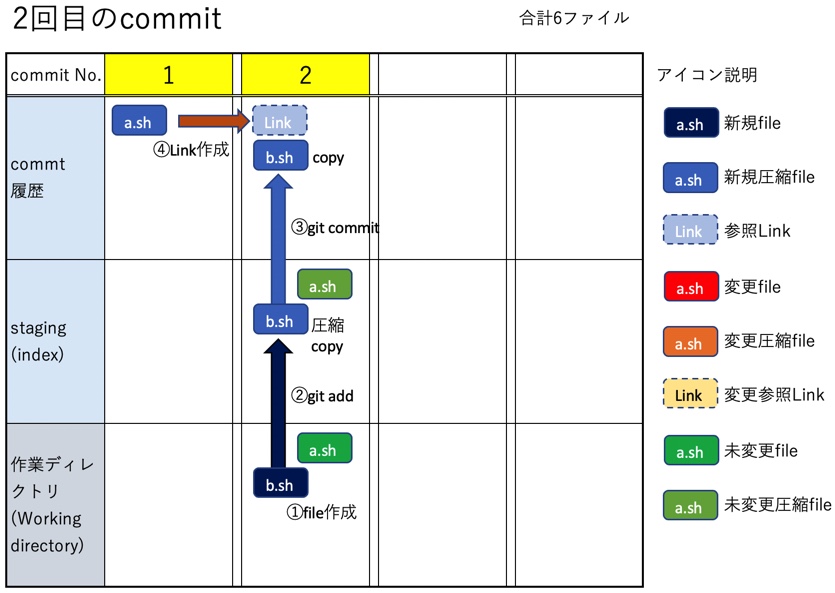
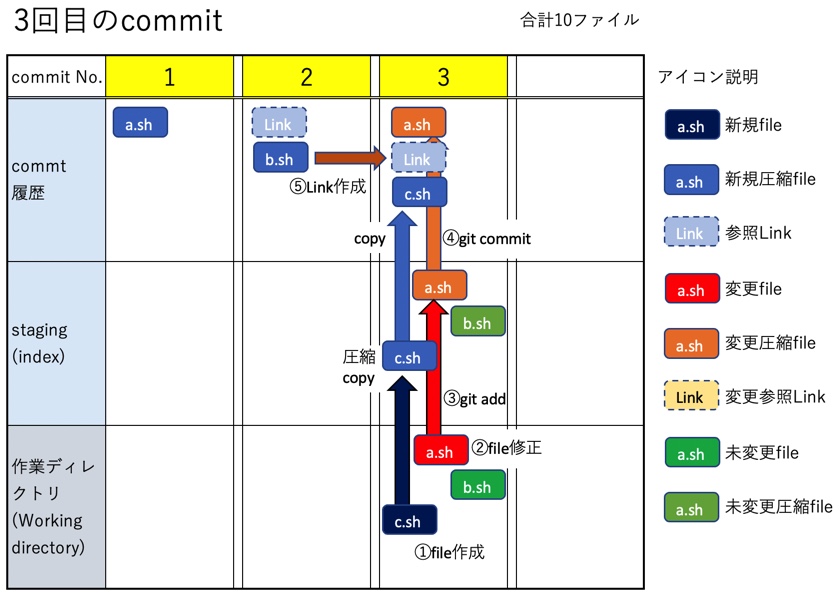
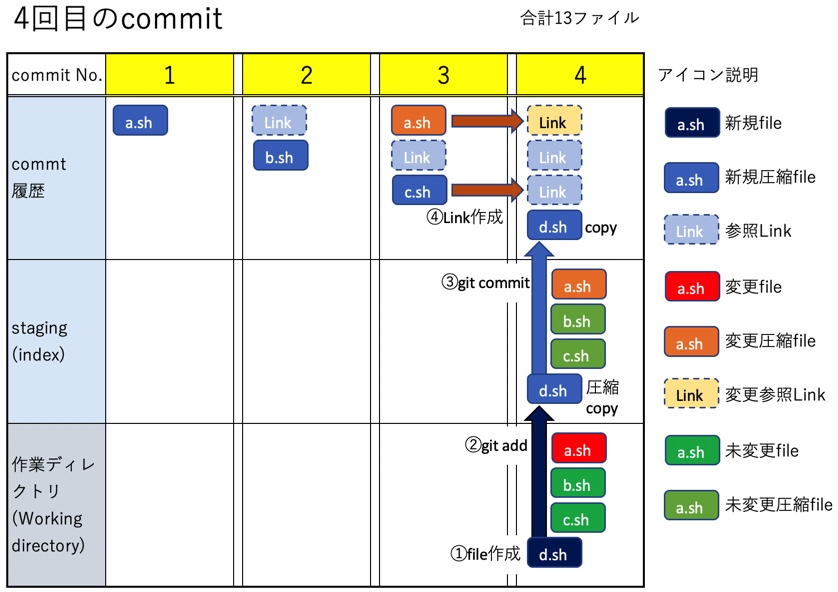
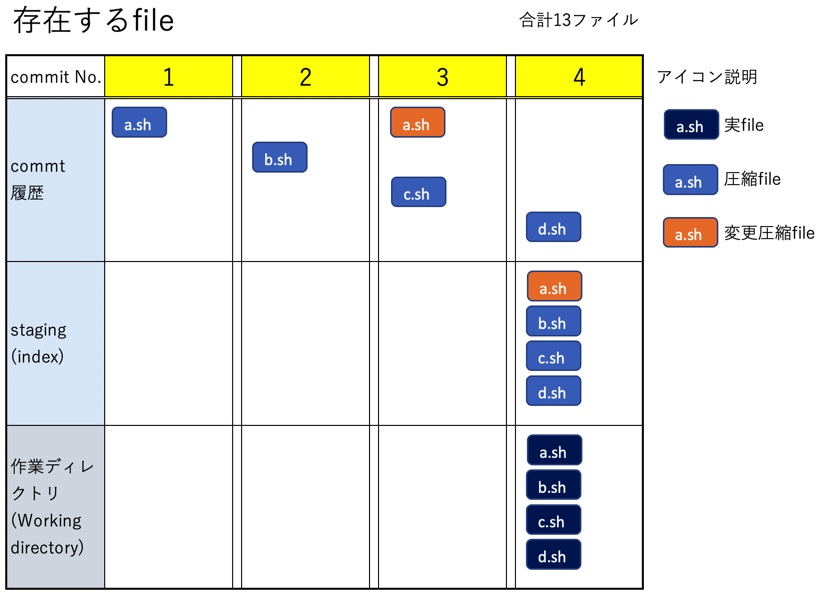
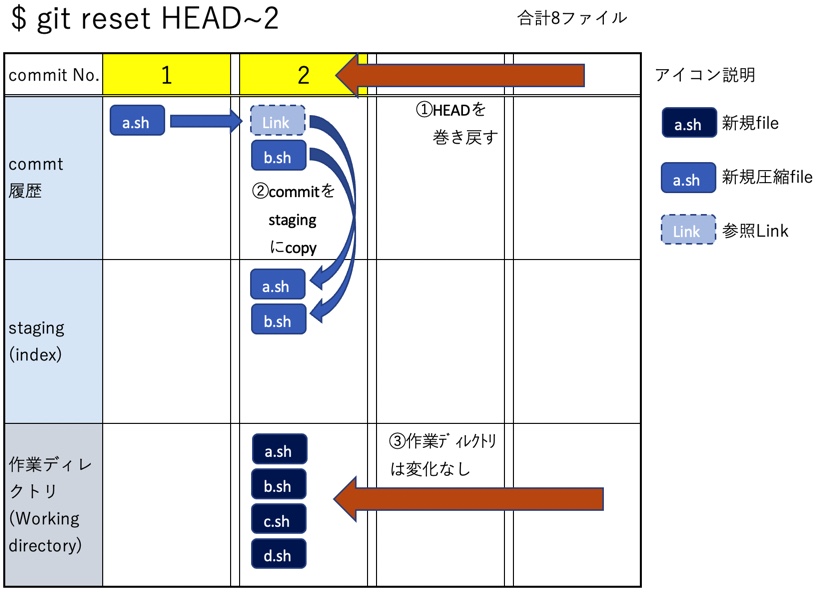
説明のために、以前の記事でまとめた内容と同じく、ブランチ数が1つ、commit数が4つ、fileもa.sh,b.sh,c.sh,d.shの4つだけのシンプルな状態を出発点とする。
programmingforever.hatenablog.com
実証のために2つブランチを作成
まずtest1ブランチを作成して、e.sh(空file)を追加してからstaging&commitを行う。
$ git checkout -b test1 Switched to a new branch 'test1' $ touch e.sh $ git add . $ git commit -m "test1のブランチ作成" [test1 6a63d27] test1のブランチ作成 1 file changed, 0 insertions(+), 0 deletions(-) create mode 100644 ee.sh $
次にtest2ブランチを作成して、f.sh(空file)を追加してからstaging&commitを行う。
$ git checkout -b test2 Switched to a new branch 'test2' $ touch f.sh $ git add . $ git commit -m "test2のブランチ作成" [test2 0e5d6c1] test2のブランチ作成 1 file changed, 0 insertions(+), 0 deletions(-) create mode 100644 ee.sh $
git worktreeコマンドを使う
ここでmainブランチに戻り、git worktreeコマンドを用いてtest1ブランチとtest2ブランチの2つを現在の作業ディレクトリの下に配置する。なお配置先は現在の作業ディレクトリの下でなくても構わないが、VSCodeなどで編集する際に各ブランチがそれぞれサブフォルダに収まっていると一覧出来て扱い易いと思う(もちろん別フォルダに置いてVSCodeのworkspace機能を使って編集しても良い)。
コマンドとしてgit worktree add サブディレクトリ名(新規) ブランチ名と打つと、指定したブランチの作業ディレクトリ一式が新規に作られるサブディレクトリ内に入る。もちろんcommit履歴などのobjectもそのまま扱える。つまり並行宇宙の様に別のブランチ一式が同時に扱える状態で存在している。初めて使った時はまるで魔法の様に感じた。
十分に発達した科学は魔法と見分けがつかない by.アーサー・クラーク
$ git checkout main Switched to branch 'main' $ git worktree add test1 test1 Preparing worktree (checking out 'test1') HEAD is now at 6a63d27 test1ブランチ作成 $ git worktree add test2 test2 Preparing worktree (checking out 'test2') HEAD is now at 0e5d6c1 test2ブランチ作成
ここでmainブランチの状態を確認すると、追加されたtest1/, test2のサブディレクトリを検出して未追跡folderだとメッセージが出るが、これらのサブディレクトリは作業完了後にGitが削除するので無視して問題ない。
$ ls a.sh b.sh c.sh d.sh test1 test2 # - 追加したサブディレクトリが見える $ git status On branch main Untracked files: (use "git add <file>..." to include in what will be committed) test1/ test2/ nothing added to commit but untracked files present (use "git add" to track)
ではtest1ブランチを入れたサブディレクトリのtest1/に移動してみよう。するとまるでこのサブディレクトリが全く別の作業ディレクトリの様に振る舞い、Gitの各コマンドも機能する。まずはtest1ブランチがクリーンな状態のままであることを確認してから、e.shを編集してcommitする。記載した様にこのcommitは現在のmainブランチとは全く関係なく、worktreeとして取り込んだtest1ブランチのcommitになる。
$ cd test1 $ ls a.sh b.sh c.sh d.sh e.sh $ git status On branch test1 nothing to commit, working tree clean $ vi e.sh $ git status On branch test1 Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git restore <file>..." to discard changes in working directory) modified: e.sh no changes added to commit (use "git add" and/or "git commit -a") $ git add . $ git status On branch test1 Changes to be committed: (use "git restore --staged <file>..." to unstage) modified: e.sh $ git commit -m "worktreeでcommit" [test1 dcadb5c] worktreeでcommit 1 file changed, 1 insertion(+)
同様にtest2ブランチを入れたサブディレクトリのtest2/に移動してから、f.shを編集してcommitする。こちらも同様にmainとは全く関係ない、worktreeとして取り込んだtest2ブランチのcommitだ。
$ cd ../test2 $ git status On branch test2 nothing to commit, working tree clean $ vi f.sh $ git add . $ git commit -m "test2のworktreeでcommit" [test2 ba6f4fe] test2のworktreeでcommit 1 file changed, 1 insertion(+)
この状態でそれぞれの作業ディレクトリに移動してログを見てみる。まずは元のmainの作業ディレクトリに移動してログを確認すると最初の4commitが確認出来る。
$ cd .. $ git log --oneline cac41d4 (HEAD -> main) 4番目のcommit 8a20ac3 3番目のcommit 1999418 2番目のcommit ef11425 最初のcommit
次にtest1サブディレクトリに移動するとtest1ブランチのログが全て確認出来る。test2ブランチのcommitは当然含まれない
$ cd ../test1 $ git log --oneline dcadb5c (HEAD -> test1) worktreeでcommit 6a63d27 test1ブランチ作成 cac41d4 (main) 4番目のcommit 8a20ac3 3番目のcommit 1999418 2番目のcommit ef11425 最初のcommit
さらにtest2サブディレクトリに移動するとtest2ブランチのログが全て確認出来る。別ブランチのtest1の"worktreeでcommit"のcommitも存在しない。
$ cd ../test2 $ git log --oneline ba6f4fe (HEAD -> test2) test2のworktreeでcommit 0e5d6c1 test2ブランチ作成 6a63d27 test1ブランチ作成 cac41d4 (main) 4番目のcommit 8a20ac3 3番目のcommit 1999418 2番目のcommit ef11425 最初のcommit
以上の様に各ブランチの編集とcommitを終えたら、不要となったworktreeを削除する。この削除は各ブランチの本体に全く影響しない。一時的に構成された仮想作業場所での用事が済んだので、その仮想作業ディレクトリを削除する行為に過ぎない。
$ cd .. $ git checkout main Switched to branch 'main' $ git worktree remove test1 $ git worktree remove test2 $ ls a.sh b.sh c.sh d.sh # - test1, test2サブディレクトリが消えた